基于 HIP 的 CPU+GPU 异构 CSR 稀疏矩阵 CG 求解
这篇文章由《并行计算》课程实验报告整理而来,保留实验思路、实现方法、核心代码、性能数据和图表,便于后续复盘。
一、实验名称与内容
本次实验名称为:基于 CPU+GPU 异构并行的 CSR 稀疏矩阵共轭梯度法求解与性能分析。
本实验针对实验二中的稀疏线性方程组求解问题,在 CSR 稀疏矩阵存储和 CG 共轭梯度法的基础上,引入 CPU+GPU 异构并行计算方式。实验要求将最耗时的稀疏矩阵向量乘法 SpMV 移植到 GPU 上执行,建议使用 HIP 编程模型。
本次实验求解的问题为:
A x = b其中,矩阵 A 为对称正定稀疏矩阵,向量 b 为右端项,程序通过 CG 迭代求得近似解向量 x。
本实验完成的主要内容包括:
- 使用
HIP实现 CSR 格式下的 GPU 稀疏矩阵向量乘SpMV; - CPU 负责 CG 迭代控制、点积计算、向量更新、收敛判断和程序输入输出;
- GPU 负责每轮迭代中的
Ap = A * p; - 矩阵数据
values、row_ptr、col_idx在 GPU 端分配并保存; - 每轮迭代前将搜索方向向量
p从主机端复制到设备端; - GPU kernel 计算完成后,将结果向量
Ap从设备端复制回主机端; - 固定
node = 1、GPU = 1,测试不同 CPU 线程数和 GPU block size 对性能的影响; - 每组实验重复运行 10 次,取平均值并将数据统一保存到
data.md。
与实验二和实验三相比,本实验的重点不再是单纯增加 CPU 线程数或 MPI 进程数,而是观察 CPU 与 GPU 分工后,GPU kernel 时间、CPU 端迭代控制、主机与设备间数据传输共同决定的异构程序性能。
二、实验环境的配置参数
本次实验环境与前几次实验使用的 PBS 高性能计算集群不同。本次实验运行在天津大学国产化大模型教学实训平台提供的异构计算环境中。该平台面向教学实验、科研创新与交叉学科实践,提供国产化智能算力与模型应用支撑。
本次实验使用的单个实验环境配置如下:
| 项目 | 配置 |
|---|---|
| CPU 型号 | Hygon C86-4G |
| 内存容量 | 90 GB |
| 存储容量 | 100 GB |
| 操作系统 | Ubuntu 22.04 |
| 异构加速卡型号 | K100 AI |
| 异构加速卡显存 | 64 GB |
| 驱动版本 | 6.3.28-V1.3.0b |
| 固定实验设置 | node = 1, GPU = 1 |
关于报告要求中的内存带宽和互联网络参数,需要说明的是:实验环境材料中给出了内存容量、CPU/GPU 型号、显存和驱动版本,但没有给出明确的内存带宽数值。由于本次实验固定在单节点单 GPU 环境下运行,不涉及跨节点通信,因此互联网络参数不作为本实验性能分析的主要因素;报告中不额外补写无法确认的网络带宽或延迟数据。
本实验采用 HIP 编程模型,编译命令为:
hipcc -O2 -fopenmp -o sparse_hip sparse_hip.cpp程序运行示例为:
./sparse_hip matrix.txt vector.txt 1000 1e-6 256运行前可以使用如下命令查看异构加速卡状态:
rocm-smi三、实验题目问题分析
本题求解的是大规模稀疏线性方程组,属于典型的科学计算数值问题。由于矩阵中绝大多数元素为零,如果采用普通二维数组存储,会造成大量无效存储和无效计算。因此程序采用 CSR 格式保存稀疏矩阵,只存储非零元及其列号和行偏移。
CG 算法适用于对称正定矩阵,其核心迭代过程主要包括:
- 稀疏矩阵向量乘:
Ap = A * p; - 点积计算:
p · Ap、r · r; - 向量更新:
x = x + alpha * p; - 残差更新:
r = r - alpha * Ap; - 搜索方向更新:
p = r + beta * p; - 收敛判断:判断相对残差是否小于给定阈值。
从计算结构看,SpMV 通常是 CG 中最耗时的部分。原因是 SpMV 需要频繁访问矩阵非零元数组、列下标数组、行指针数组和输入向量。它的浮点计算量不算特别高,但访存访问多且不完全连续,是典型的访存敏感型计算。因此,将 SpMV 卸载到 GPU 上执行,是本实验异构并行加速的主要切入点。
CSR 格式下,第 i 行的计算为:
y[i] = sum(values[j] * x[col_idx[j]]), j = row_ptr[i] ... row_ptr[i+1]-1每一行输出 y[i] 只由该行的非零元和输入向量决定,不同输出行之间没有写冲突。因此,最自然的 GPU 并行方式是“一个线程负责一行”。对于本实验生成的带状稀疏矩阵,每行非零元数量较少且比较均匀,因此这种实现方式结构清晰,适合作为本实验的主要实现方案。
本题可以考虑的并行化方案包括:
- CPU 多线程方案:将
SpMV、点积和向量更新全部放在 CPU 上,用 OpenMP 或 Pthread 并行; - GPU 完全卸载方案:将
SpMV、点积和向量更新都放到 GPU 上,减少主机与设备间数据传输; - CPU+GPU 简化异构方案:CPU 负责流程、点积和向量更新,GPU 只负责最耗时的
SpMV; - MPI+GPU 混合方案:多节点多 GPU 划分矩阵行块,节点内使用 GPU,节点间使用 MPI 通信。
结合本次实验要求和实现复杂度,本实验采用第三种方案,即 CPU+GPU 简化异构方案。
实验二主要考察 Pthread 共享内存多线程并行,实验三主要考察 MPI 多进程和多节点并行;本次实验则考察异构并行。因此,本次不再设置类似实验三中的 nodes 和 ppn 组合。实验环境固定为单节点单 GPU:
node = 1
GPU = 1在此基础上,本实验设置两个变量:
- CPU 线程数:
1, 2, 4, 8, 16; - GPU block size:
128, 256, 512。
这样既能观察 CPU 端点积和向量更新并行化的影响,也能观察 GPU kernel block size 对 SpMV 的影响。
四、方案设计
4.1 异构分工总体设计
本实验采用“CPU 控制流程,GPU 执行 SpMV”的异构方案。CPU 端保留 CG 算法的主循环,负责点积、向量更新、收敛判断和时间统计;GPU 端只执行 CSR 稀疏矩阵向量乘。
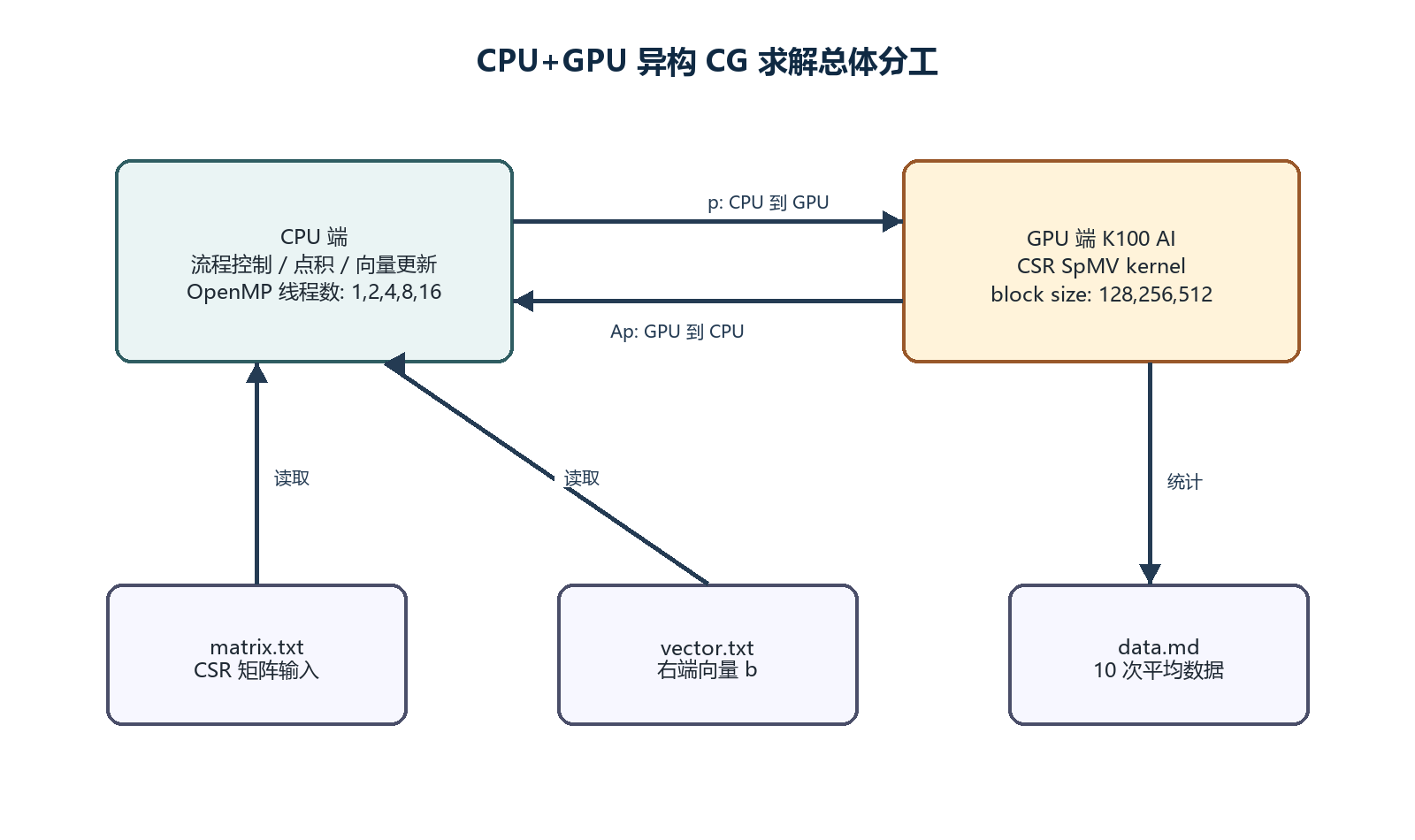
这种方案的优点是实现清晰,能够直接对应实验要求中“仅将 SpMV 卸载到 GPU”的建议。它的不足是每轮迭代仍然需要传输 p 和 Ap,因此总体加速会受到 CPU-GPU 数据传输的限制。
4.2 CG 迭代流程设计
CG 算法的每一轮迭代都存在前后依赖关系。例如,只有计算出 p · Ap 后才能得到 alpha,只有更新残差后才能判断是否收敛。因此,CG 不能把不同迭代轮次完全并行化,只能在每一轮内部对 SpMV、点积和向量更新进行并行。
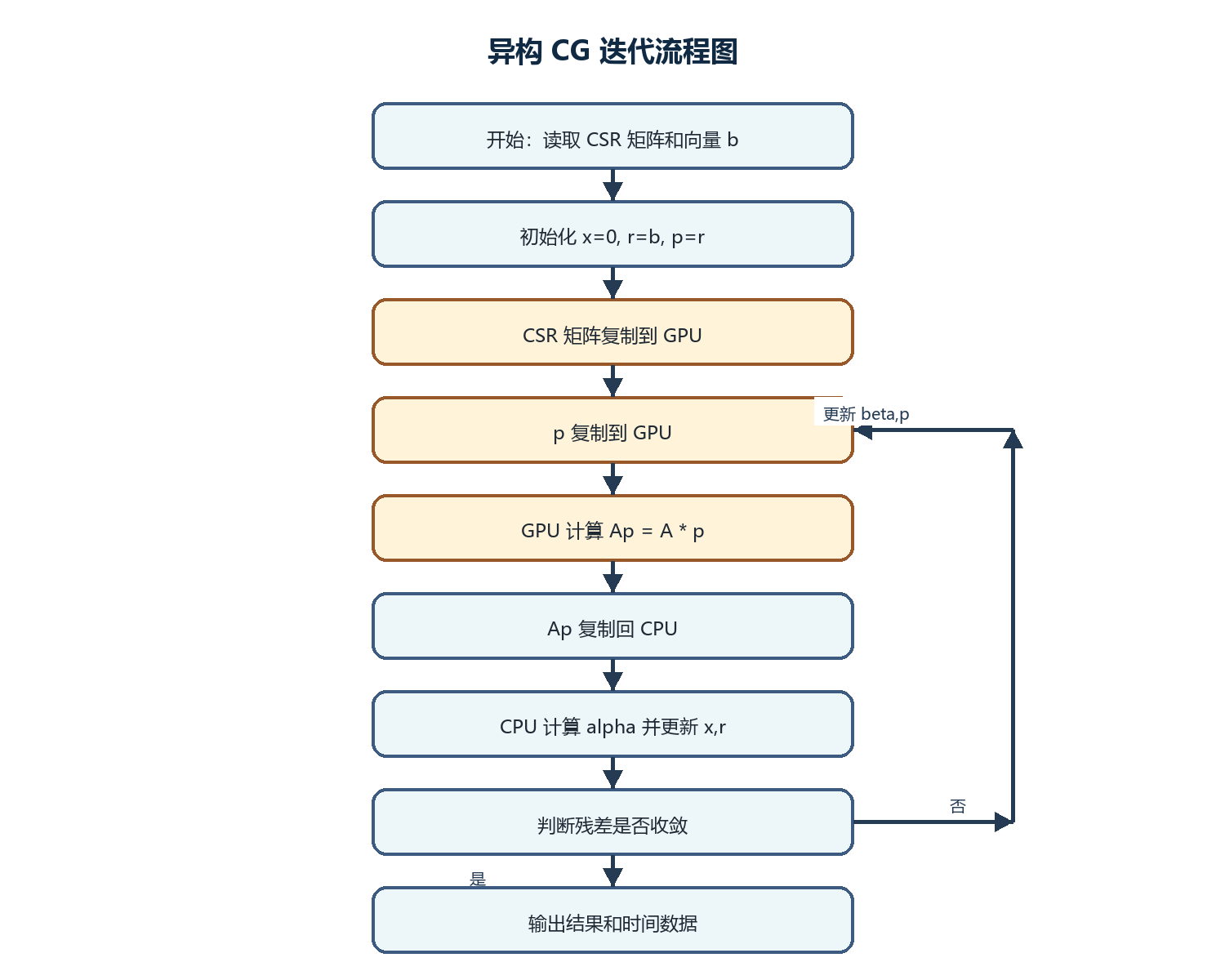
本实验中的一轮迭代流程为:
- CPU 将当前搜索方向
p复制到 GPU; - GPU 执行
SpMVkernel,计算Ap = A * p; - CPU 将
Ap从 GPU 复制回主机端; - CPU 计算
p · Ap,得到步长alpha; - CPU 更新
x和r; - CPU 计算新的残差平方和;
- 若满足收敛阈值则退出,否则计算
beta并更新p。
4.3 CSR SpMV 并行映射设计
CSR 格式中每一行的输出互不冲突,因此本实验采用一行一线程的 GPU 映射方式。
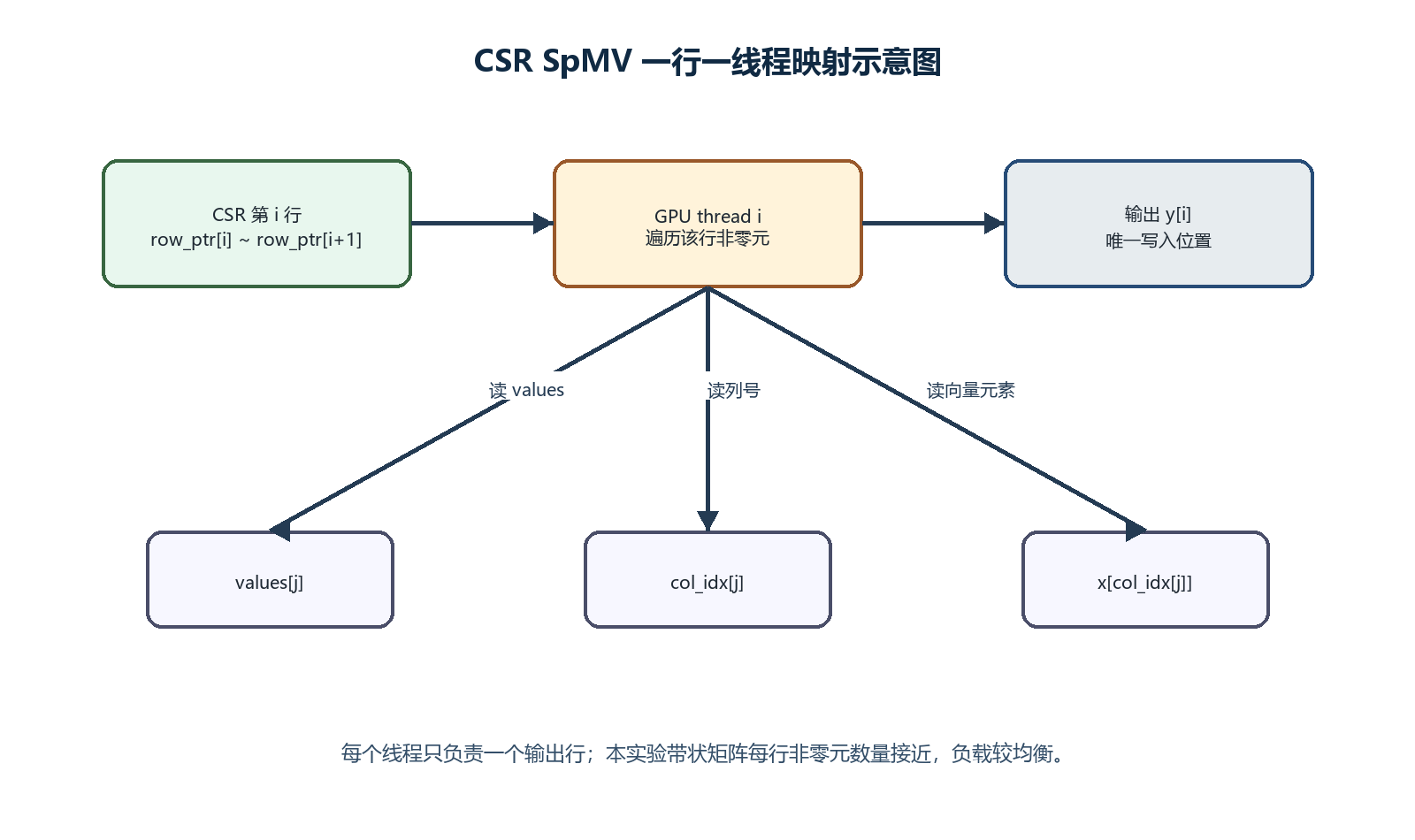
对于第 row 行,GPU 线程遍历该行的所有非零元,累加:
y[row] += values[j] * x[col_idx[j]]由于每个线程只写一个唯一的 y[row],因此不存在写冲突,也不需要使用原子操作。对于本实验的带状矩阵,每行非零元数量接近,一行一线程的负载比较均衡。
4.4 并行算法伪代码
本实验异构 CG 算法伪代码如下:
Input: CSR matrix A(values, row_ptr, col_idx), vector b
Output: approximate solution x
x = 0
r = b
p = r
rr_old = dot(r, r)
copy CSR matrix A to GPU
for iter = 1 to max_iter:
copy p from CPU to GPU
launch GPU kernel: Ap = A * p
synchronize GPU
copy Ap from GPU to CPU
pAp = parallel_dot_cpu(p, Ap)
alpha = rr_old / pAp
parallel_for_cpu i = 0 ... n-1:
x[i] = x[i] + alpha * p[i]
r[i] = r[i] - alpha * Ap[i]
rr_new = parallel_dot_cpu(r, r)
if sqrt(rr_new) / norm_b < tol:
break
beta = rr_new / rr_old
parallel_for_cpu i = 0 ... n-1:
p[i] = r[i] + beta * p[i]
rr_old = rr_new其中 parallel_dot_cpu 和 parallel_for_cpu 由 OpenMP 在 CPU 端并行执行,Ap = A * p 由 HIP kernel 在 GPU 端并行执行。
五、实现方法
5.1 输入数据与文件组织
本实验使用的大规模输入数据如下:
| 参数 | 数值 |
|---|---|
矩阵维度 n | 1,000,000 |
非零元个数 nnz | 6,999,988 |
| 矩阵类型 | 对称正定带状稀疏矩阵 |
| 带宽参数 | 3 |
| 最大迭代次数 | 1000 |
| 收敛阈值 | 1e-6 |
| 重复次数 | 每组 10 次 |
矩阵生成程序采用带状结构:每一行最多包含主对角线及左右各 3 个邻接位置,因此内部行大约有 7 个非零元,边界行略少。这一结构既适合 CSR 压缩存储,也使得一行一线程的 GPU SpMV 映射具有较均衡的负载。与实验三的 MPI 版本不同,本实验固定在单节点单 GPU 上运行,因此不需要对矩阵做跨节点划分,而是将完整 CSR 矩阵一次性复制到 GPU 设备端。
本实验矩阵仍采用 CSR 存储结构,核心数组包括 values、row_ptr 和 col_idx。其中 values 保存非零元数值,col_idx 保存对应列号,row_ptr 给出每一行非零元在 values 中的起止位置。GPU kernel 中每个线程根据 row_ptr[row] 到 row_ptr[row + 1] 的范围遍历一行非零元,计算得到 Ap[row]。
本实验的文件组织围绕输入生成、异构求解、批量测试和数据记录展开。主要文件如下:
| 文件 | 作用 |
|---|---|
sparse_hip.cpp | HIP 异构 CG 主程序,包含 GPU SpMV kernel 和 CPU 端 CG 控制逻辑 |
generate_input.cpp | 生成对称正定带状稀疏矩阵和右端向量 |
matrix.txt | CSR 稀疏矩阵输入文件 |
vector.txt | 右端向量输入文件 |
run_lab4.sh | 单次编译运行脚本 |
benchmark_lab4.sh | 批量测试脚本,每组运行 10 次并写入 data.md |
data.md | 批量测试后生成的实验统计数据,包含 Summary 和 Raw Data |
5.2 程序头文件与命名空间
主程序 sparse_hip.cpp 使用 HIP 运行时接口、C 标准文件接口、数学函数、系统时间函数以及 OpenMP。为了使后续代码书写更简洁,程序中使用了 using namespace std;。该写法不会影响程序性能,只是减少 std:: 前缀。
#include <hip/hip_runtime.h>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <sys/time.h>
using namespace std;其中,hip/hip_runtime.h 提供 hipMalloc、hipMemcpy、hipDeviceSynchronize 和 kernel 启动相关接口;sys/time.h 用于通过 gettimeofday 统计程序运行时间。
5.3 快速输入读取实现
本实验矩阵规模为 n = 1,000,000、nnz = 6,999,988,输入文件较大。若直接使用 cin 读取,可能带来明显 I/O 开销。因此程序实现了基于 fread 缓冲区的 FastScanner,用于快速读取整数和浮点数。
class FastScanner
{
private:
static const int BUF_SIZE = 1 << 20;
FILE* fp;
char buf[BUF_SIZE];
int pos;
int len;
int read_char()
{
if (pos >= len)
{
len = (int)fread(buf, 1, BUF_SIZE, fp);
pos = 0;
if (len == 0)
{
return EOF;
}
}
return buf[pos++];
}
int skip_blank()
{
int c = read_char();
while (c != EOF && (c == ' ' || c == '\n' || c == '\r' || c == '\t'))
{
c = read_char();
}
return c;
}
public:
explicit FastScanner(FILE* file) : fp(file), pos(0), len(0) {}
bool read_int(int& out);
bool read_long_long(long long& out);
bool read_double(double& out);
};在完整代码中,read_int、read_long_long 和 read_double 分别负责读取整数、长整数和浮点数。这里使用 1 << 20 大小的缓冲区,减少系统调用次数,提高大文件读取效率。
矩阵读取函数根据文件头中的 n 和 nnz 分配 CSR 三个数组:
static void read_matrix(const char* path, int& n, long long& nnz,
double*& values, int*& row_ptr, int*& col_idx)
{
FILE* fp = fopen(path, "r");
if (fp == NULL)
{
fprintf(stderr, "Failed to open matrix file: %s\n", path);
exit(1);
}
FastScanner fs(fp);
if (!fs.read_int(n) || !fs.read_long_long(nnz) || n <= 0 || nnz <= 0)
{
fprintf(stderr, "Invalid matrix file format\n");
fclose(fp);
exit(1);
}
values = (double*)malloc((size_t)nnz * sizeof(double));
row_ptr = (int*)malloc((size_t)(n + 1) * sizeof(int));
col_idx = (int*)malloc((size_t)nnz * sizeof(int));
if (values == NULL || row_ptr == NULL || col_idx == NULL)
{
fprintf(stderr, "Host CSR memory allocation failed\n");
fclose(fp);
exit(1);
}
for (long long i = 0; i < nnz; i++)
{
if (!fs.read_double(values[i]))
{
fprintf(stderr, "Failed to read values[%lld]\n", i);
fclose(fp);
exit(1);
}
}
}5.4 稀疏矩阵生成
本实验使用 generate_input.cpp 生成对称正定带状稀疏矩阵。正式实验输入规模为:
n = 1,000,000
nnz = 6,999,988
bandwidth = 3
seed = 42为了保证 CG 迭代能够稳定收敛,矩阵生成时采用强对角占优构造。每一行的非对角元素先随机生成,然后对角元按如下方式设置:
diag = 2.0 * offdiag_sum + 10.0这样可以增强矩阵的正定性和数值稳定性,避免 CG 因矩阵性质不满足要求而出现残差不下降或迭代异常。
5.5 CSR 存储实现
矩阵采用 CSR 格式保存,主要包含三个数组:
values:按行存储所有非零元的数值;col_idx:存储每个非零元所在的列号;row_ptr:长度为n + 1,用于标记每一行非零元在values中的起止位置。
对于第 i 行,其非零元范围为:
for (int j = row_ptr[i]; j < row_ptr[i + 1]; ++j) {
y[i] += values[j] * x[col_idx[j]];
}CSR 格式能够避免存储零元素,适合本实验这种大规模稀疏矩阵。
5.6 HIP 错误检查与 kernel 实现
为了避免 HIP API 调用失败后程序继续运行,代码定义了 HIP_CHECK 宏。每次调用 hipMalloc、hipMemcpy、hipDeviceSynchronize 等接口时,都通过该宏检查返回值。
#define HIP_CHECK(call) \
do \
{ \
hipError_t err = (call); \
if (err != hipSuccess) \
{ \
fprintf(stderr, "HIP error %s:%d: %s\n", __FILE__, __LINE__, \
hipGetErrorString(err)); \
exit(1); \
} \
} while (0)GPU kernel 的基本思路是一个线程计算一行:
__global__ __launch_bounds__(1024) void spmv_csr_kernel(int n,
const double* values,
const int* row_ptr,
const int* col_idx,
const double* p,
double* Ap)
{
int row = blockIdx.x * blockDim.x + threadIdx.x;
if (row >= n)
{
return;
}
double sum = 0.0;
int begin = row_ptr[row];
int end = row_ptr[row + 1];
for (int j = begin; j < end; j++)
{
sum += values[j] * p[col_idx[j]];
}
Ap[row] = sum;
}启动 kernel 时,线程块大小由命令行参数指定,实验中测试 128、256、512 三种 block size。网格大小按如下方式计算:
int grid_size = (n + block_size - 1) / block_size;kernel 启动后调用 hipDeviceSynchronize(),确保 GPU 计算完成后再统计时间。
5.7 CPU 端 OpenMP 实现
为了让 CPU 线程数成为可控实验变量,CPU 端点积和向量更新部分使用 OpenMP 进行并行化。例如点积采用 reduction:
static double dot(int n, const double* a, const double* b)
{
double sum = 0.0;
#pragma omp parallel for reduction(+ : sum) schedule(static)
for (int i = 0; i < n; i++)
{
sum += a[i] * b[i];
}
return sum;
}在 CG 主循环中,x、r 和 p 的向量更新也采用 OpenMP 并行:
#pragma omp parallel for schedule(static)
for (int i = 0; i < n; i++)
{
x[i] += alpha * p[i];
r[i] -= alpha * Ap[i];
}
double rho_new = dot(n, r, r);
double beta = rho_new / rho;
#pragma omp parallel for schedule(static)
for (int i = 0; i < n; i++)
{
p[i] = r[i] + beta * p[i];
}运行批量实验时,通过设置 OMP_NUM_THREADS 控制 CPU 线程数:
export OMP_NUM_THREADS=8因此,本实验中的 CPU 线程数主要影响 CPU 端点积、残差计算和向量更新,不直接改变 GPU 上 SpMV 的行级并行方式。
5.8 GPU 内存分配与数据传输实现
程序开始 CG 计算前,先在 GPU 端分配 CSR 矩阵和向量空间,并将矩阵数据一次性复制到设备端:
double* d_values = NULL;
int* d_row_ptr = NULL;
int* d_col_idx = NULL;
double* d_p = NULL;
double* d_Ap = NULL;
HIP_CHECK(hipMalloc((void**)&d_values, (size_t)nnz * sizeof(double)));
HIP_CHECK(hipMalloc((void**)&d_row_ptr, (size_t)(n + 1) * sizeof(int)));
HIP_CHECK(hipMalloc((void**)&d_col_idx, (size_t)nnz * sizeof(int)));
HIP_CHECK(hipMalloc((void**)&d_p, (size_t)n * sizeof(double)));
HIP_CHECK(hipMalloc((void**)&d_Ap, (size_t)n * sizeof(double)));
HIP_CHECK(hipMemcpy(d_values, values,
(size_t)nnz * sizeof(double), hipMemcpyHostToDevice));
HIP_CHECK(hipMemcpy(d_row_ptr, row_ptr,
(size_t)(n + 1) * sizeof(int), hipMemcpyHostToDevice));
HIP_CHECK(hipMemcpy(d_col_idx, col_idx,
(size_t)nnz * sizeof(int), hipMemcpyHostToDevice));
HIP_CHECK(hipDeviceSynchronize());这里矩阵数据只复制一次,避免每轮迭代重复传输大矩阵。每轮迭代只传输搜索方向向量 p 和结果向量 Ap:
HIP_CHECK(hipMemcpy(d_p, p, (size_t)n * sizeof(double), hipMemcpyHostToDevice));
double spmv_start = now_seconds();
hipLaunchKernelGGL(spmv_csr_kernel,
dim3(grid_size),
dim3(block_size),
0,
0,
n,
d_values,
d_row_ptr,
d_col_idx,
d_p,
d_Ap);
HIP_CHECK(hipGetLastError());
HIP_CHECK(hipDeviceSynchronize());
spmv_total_time += now_seconds() - spmv_start;
HIP_CHECK(hipMemcpy(Ap, d_Ap, (size_t)n * sizeof(double), hipMemcpyDeviceToHost));这段代码体现了本实验的核心异构数据流:p 从 CPU 到 GPU,GPU 计算出 Ap 后再复制回 CPU。
5.9 CG 主循环实现
主程序中,先初始化 x、r、p,然后进入 CG 迭代。由于初始解 x = 0,所以初始残差 r = b,初始搜索方向 p = r:
#pragma omp parallel for schedule(static)
for (int i = 0; i < n; i++)
{
r[i] = b[i];
p[i] = r[i];
}
double rho = dot(n, r, r);
double initial_res_norm = sqrt(rho);CG 主循环的关键代码如下:
for (iter = 0; iter < max_iter; iter++)
{
HIP_CHECK(hipMemcpy(d_p, p, (size_t)n * sizeof(double), hipMemcpyHostToDevice));
double spmv_start = now_seconds();
hipLaunchKernelGGL(spmv_csr_kernel,
dim3(grid_size),
dim3(block_size),
0,
0,
n,
d_values,
d_row_ptr,
d_col_idx,
d_p,
d_Ap);
HIP_CHECK(hipGetLastError());
HIP_CHECK(hipDeviceSynchronize());
spmv_total_time += now_seconds() - spmv_start;
HIP_CHECK(hipMemcpy(Ap, d_Ap, (size_t)n * sizeof(double), hipMemcpyDeviceToHost));
double pAp = dot(n, p, Ap);
if (fabs(pAp) < 1e-20)
{
printf("Break: pAp is too small at iteration %d\n", iter + 1);
break;
}
double alpha = rho / pAp;
#pragma omp parallel for schedule(static)
for (int i = 0; i < n; i++)
{
x[i] += alpha * p[i];
r[i] -= alpha * Ap[i];
}
double rho_new = dot(n, r, r);
double res_norm = sqrt(rho_new);
if (res_norm / initial_res_norm < tol)
{
rho = rho_new;
iter++;
break;
}
double beta = rho_new / rho;
#pragma omp parallel for schedule(static)
for (int i = 0; i < n; i++)
{
p[i] = r[i] + beta * p[i];
}
rho = rho_new;
}可以看到,该循环中 GPU 只负责 Ap = A*p,而 pAp 点积、alpha、beta 计算以及向量更新仍在 CPU 上完成。这与实验要求中的简化异构策略一致。
5.10 计时与输出实现
实验要求统计 kernel 运行时间,并使用系统时间戳。因此程序用 gettimeofday 封装了计时函数:
static double now_seconds()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return (double)tv.tv_sec + (double)tv.tv_usec / 1000000.0;
}程序输出的关键指标包括:
printf("n = %d, nnz = %lld\n", n, nnz);
printf("GPU block size: %d\n", block_size);
printf("Read input time: %.6f s\n", read_time);
printf("GPU allocation and CSR copy time: %.6f s\n", gpu_alloc_time);
printf("CG time: %.6f s, iterations: %d\n", cg_time, iter);
printf("GPU SpMV kernel total time: %.6f s\n", spmv_total_time);
printf("Total program time: %.6f s\n", total_time);
printf("Final relative residual: %.6e\n", final_rel_res);这些输出字段会被批量测试脚本解析,并写入 data.md。
5.11 数据统计实现
本实验固定:
node = 1
GPU = 1批量测试脚本对如下组合进行测试:
CPU threads = 1, 2, 4, 8, 16
GPU block size = 128, 256, 512批量脚本 benchmark_lab4.sh 的核心设置如下:
MATRIX_FILE="${1:-matrix.txt}"
VECTOR_FILE="${2:-vector.txt}"
MAX_ITER="${3:-1000}"
TOL="${4:-1e-6}"
REPEAT="${5:-10}"
THREADS_LIST="1 2 4 8 16"
BLOCK_LIST="128 256 512"
hipcc -O2 -fopenmp -o sparse_hip sparse_hip.cpp脚本通过双层循环遍历 CPU 线程数和 GPU block size,每组重复运行 REPEAT 次:
for threads in ${THREADS_LIST}; do
export OMP_NUM_THREADS="${threads}"
for block_size in ${BLOCK_LIST}; do
for run in $(seq 1 "${REPEAT}"); do
log_file="bench_t${threads}_b${block_size}_r${run}.log"
./sparse_hip "${MATRIX_FILE}" "${VECTOR_FILE}" \
"${MAX_ITER}" "${TOL}" "${block_size}" > "${log_file}"
n=$(awk -F'[ =,]+' '/^n =/{print $2}' "${log_file}")
nnz=$(awk -F'[ =,]+' '/^n =/{print $4}' "${log_file}")
iterations=$(awk '/CG time:/{print $6}' "${log_file}")
read_time=$(awk '/Read input time:/{print $4}' "${log_file}")
cg_time=$(awk '/CG time:/{print $3}' "${log_file}")
spmv_time=$(awk '/GPU SpMV kernel total time:/{print $6}' "${log_file}")
total_time=$(awk '/Total program time:/{print $4}' "${log_file}")
final_res=$(awk '/Final relative residual:/{print $4}' "${log_file}")
done
done
done每组实验运行 10 次,脚本从程序输出中提取读取时间、CG 时间、SpMV 时间、总时间、迭代次数和最终相对残差,并将平均结果和原始数据全部写入 data.md。本实验不额外使用 CSV 文件保存数据,脚本中临时中间文件在结束时删除。
SECTION_5_12_REPLACEMENT
六、结果分析
6.1 实验数据汇总
本实验数据统一保存在 data.md 中。每组实验重复 10 次后取平均值,汇总结果如下。
| CPU 线程数 | GPU block size | 平均迭代次数 | 平均读取时间/s | 平均 CG 时间/s | 平均 GPU SpMV 时间/s | 平均总时间/s | 平均最终相对残差 |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 12.00 | 0.296340 | 0.100832 | 0.020348 | 0.530354 | 5.332733e-07 |
| 1 | 256 | 12.00 | 0.298864 | 0.104877 | 0.024764 | 0.534551 | 5.332733e-07 |
| 1 | 512 | 12.00 | 0.299199 | 0.103851 | 0.023738 | 0.535683 | 5.332733e-07 |
| 2 | 128 | 12.00 | 0.297992 | 0.076337 | 0.020627 | 0.502798 | 5.332733e-07 |
| 2 | 256 | 12.00 | 0.303617 | 0.078109 | 0.022143 | 0.510997 | 5.332733e-07 |
| 2 | 512 | 12.00 | 0.298215 | 0.078086 | 0.022314 | 0.502964 | 5.332733e-07 |
| 4 | 128 | 12.00 | 0.299858 | 0.062805 | 0.019870 | 0.486382 | 5.332733e-07 |
| 4 | 256 | 12.00 | 0.299948 | 0.064948 | 0.021841 | 0.488100 | 5.332733e-07 |
| 4 | 512 | 12.00 | 0.298038 | 0.065232 | 0.022062 | 0.489362 | 5.332733e-07 |
| 8 | 128 | 12.00 | 0.299901 | 0.058565 | 0.019801 | 0.483763 | 5.332733e-07 |
| 8 | 256 | 12.00 | 0.301438 | 0.060718 | 0.021808 | 0.488416 | 5.332733e-07 |
| 8 | 512 | 12.00 | 0.298819 | 0.060934 | 0.021981 | 0.486389 | 5.332733e-07 |
| 16 | 128 | 12.00 | 0.300510 | 0.060584 | 0.020296 | 0.512299 | 5.332733e-07 |
| 16 | 256 | 12.00 | 0.298836 | 0.062534 | 0.022876 | 0.493867 | 5.332733e-07 |
| 16 | 512 | 12.00 | 0.301132 | 0.062428 | 0.022120 | 0.504167 | 5.332733e-07 |
所有实验组合均在 12 次迭代后收敛,最终相对残差均为 5.332733e-07,小于设定阈值 1e-6。这说明不同 CPU 线程数和不同 GPU block size 只影响性能,不影响本次实验结果的正确性和收敛性。
6.2 重复实验稳定性
每组实验运行 10 次后再取平均值,可以减小单次运行抖动对结论的影响。从原始数据看,大部分组合的 CG 时间标准差在 0.001 s 左右,说明求解阶段的时间比较稳定。例如:
| CPU threads | GPU block size | CG time 标准差/s | SpMV time 标准差/s | total time 标准差/s |
|---|---|---|---|---|
| 1 | 128 | 0.000533 | 0.000679 | 0.002717 |
| 4 | 128 | 0.000790 | 0.000614 | 0.004260 |
| 8 | 128 | 0.000991 | 0.000429 | 0.003574 |
| 16 | 128 | 0.002096 | 0.001411 | 0.012323 |
可以看出,CG time 的波动明显小于 total time。这是因为 total time 包含文件读取、内存分配和设备初始化等开销,这些部分更容易受到系统状态影响。16 线程下总时间波动更明显,也说明线程数过多时调度和资源竞争会使完整程序运行时间更不稳定。
6.3 平均 CG 时间对比
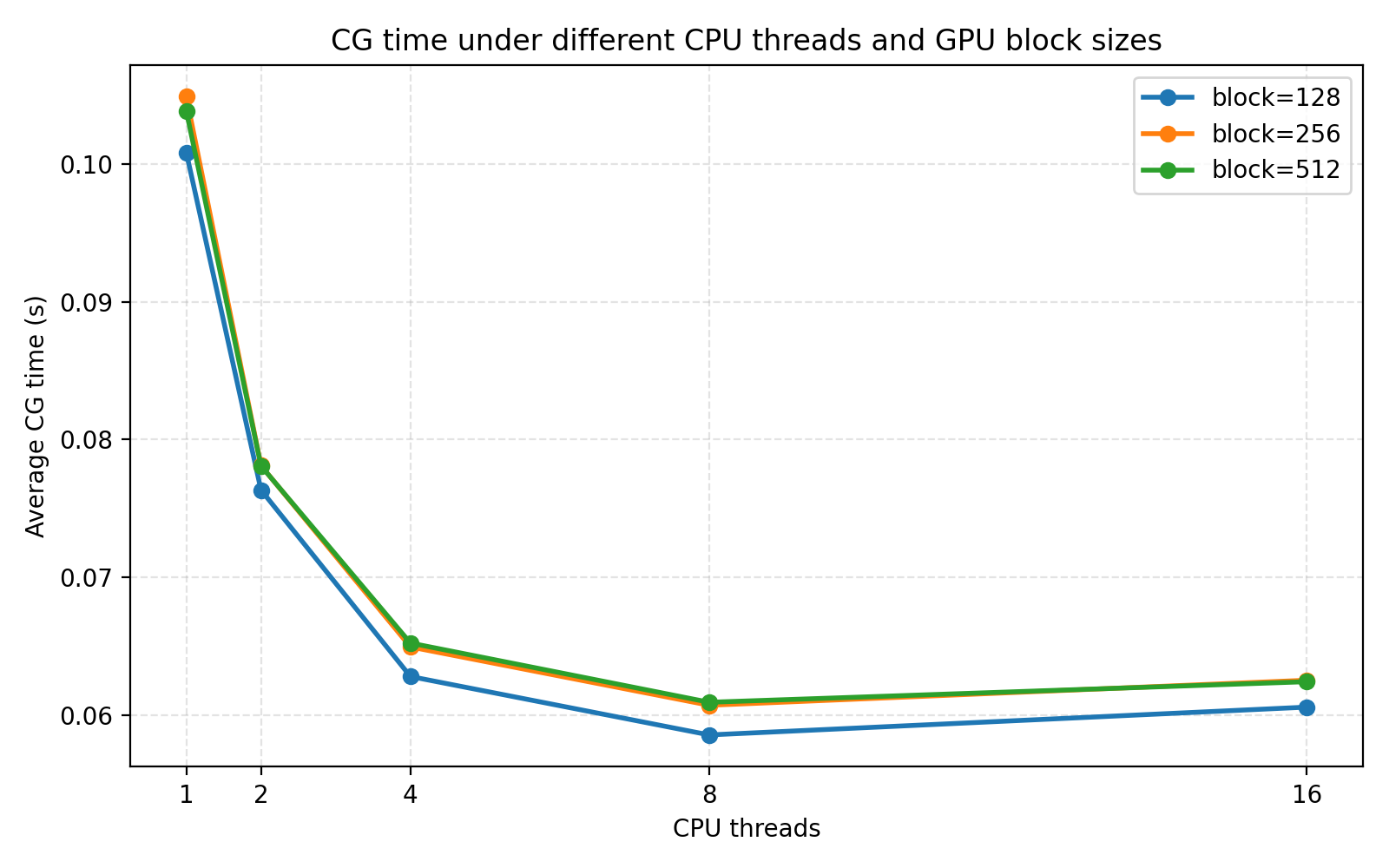
从图中可以看出,当 GPU block size 固定时,CPU 线程数从 1 增加到 8,平均 CG 时间明显下降。以 block size = 128 为例:
1 线程:0.100832 s
2 线程:0.076337 s
4 线程:0.062805 s
8 线程:0.058565 s
16 线程:0.060584 s线程数从 1 增加到 8 时,CG 时间由 0.100832 s 降至 0.058565 s,加速效果明显;但继续增加到 16 线程后,时间反而略有上升。这说明 CPU 端并行部分并不是无限可扩展的。当线程数过多时,OpenMP 调度开销、线程同步开销、内存带宽竞争以及 CPU 与 GPU 之间固定传输开销会限制进一步加速。
6.4 GPU SpMV kernel 时间对比
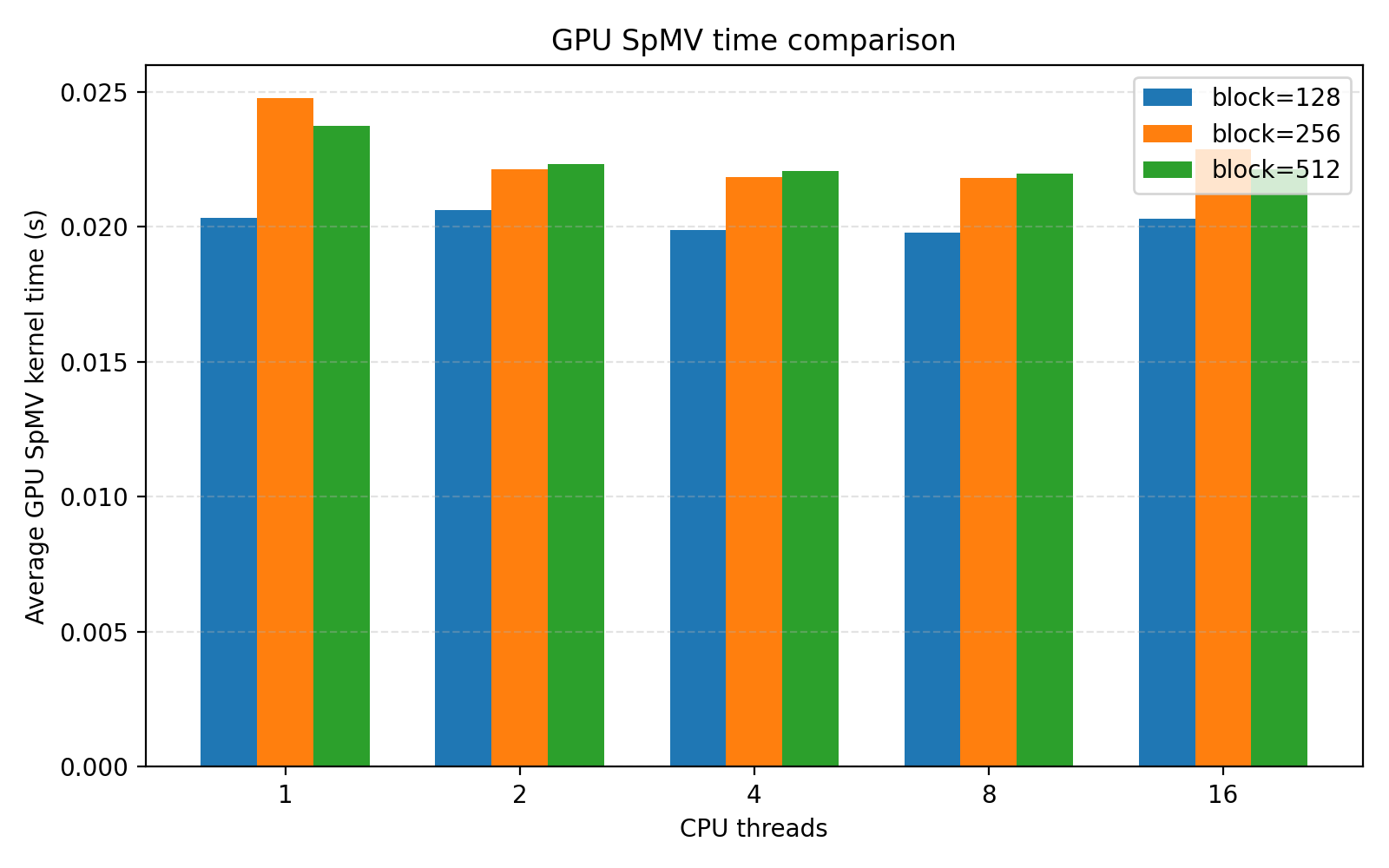
从 SpMV 时间看,block size = 128 在大多数 CPU 线程数下表现最好。例如:
8 线程,block=128:0.019801 s
8 线程,block=256:0.021808 s
8 线程,block=512:0.021981 s本实验矩阵为带状稀疏矩阵,每行非零元数量较少,单个线程处理一行时计算量并不大。在这种情况下,较大的 block size 并不一定带来更高性能,反而可能因为调度粒度、访存模式和资源占用等因素导致 kernel 时间略有上升。因此,本次实验中 block size = 128 是更合适的选择。
6.5 加速比与效率分析
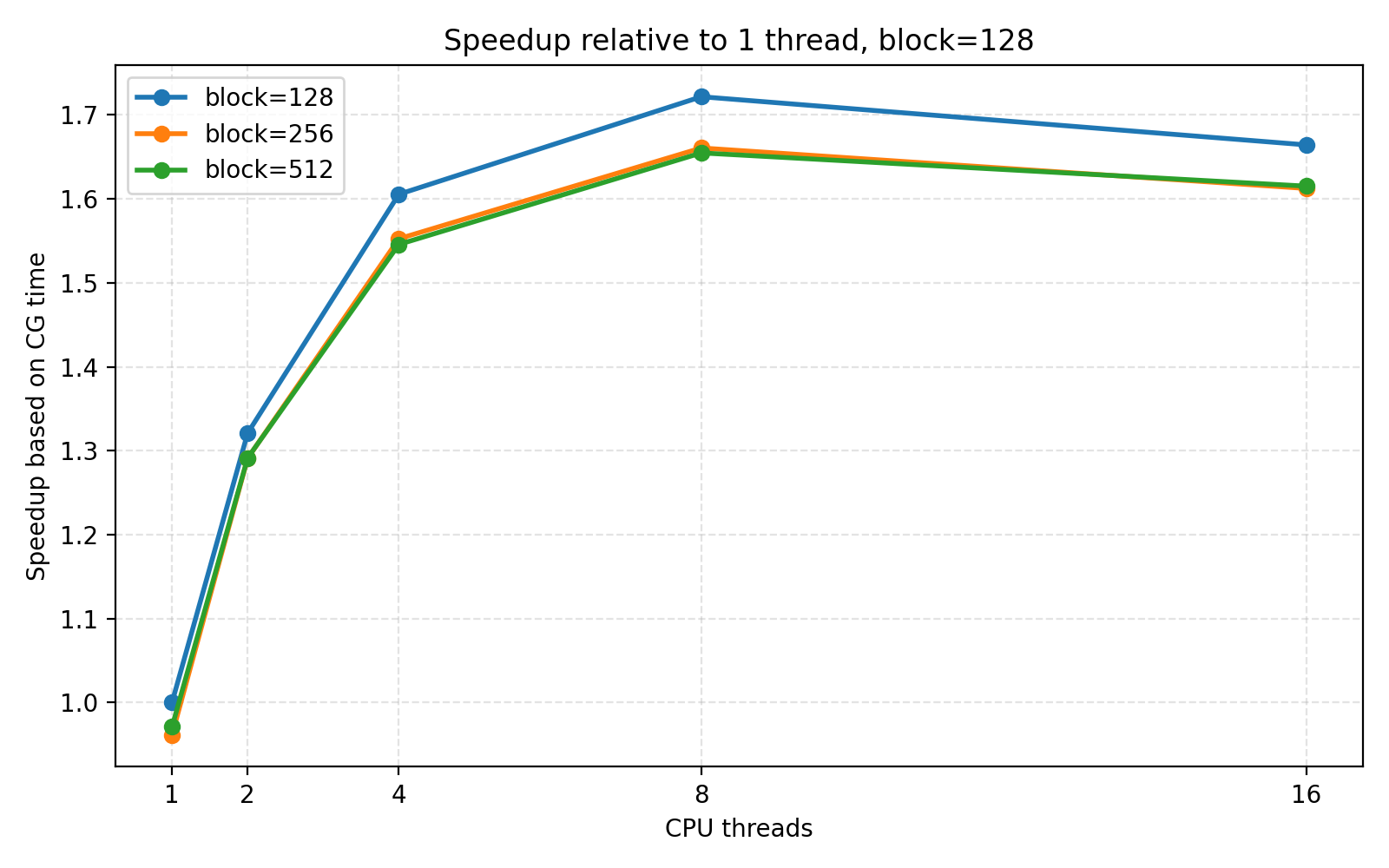
以 CPU threads = 1, block size = 128 作为基准,基准 CG 时间为 0.100832 s。block size = 128 下的 CPU 线程扩展加速比和效率如下:
| CPU threads | avg CG time/s | Speedup | Efficiency |
|---|---|---|---|
| 1 | 0.100832 | 1.000 | 1.000 |
| 2 | 0.076337 | 1.321 | 0.660 |
| 4 | 0.062805 | 1.605 | 0.401 |
| 8 | 0.058565 | 1.722 | 0.215 |
| 16 | 0.060584 | 1.664 | 0.104 |
最佳组合为:
CPU threads = 8
GPU block size = 128
avg CG time = 0.058565 s对应加速比为:
S = 0.100832 / 0.058565 ≈ 1.72这里的效率不是传统 MPI 多节点扩展效率,而是在固定单 GPU 条件下,用 CPU 线程数作为并行规模计算的线程扩展效率。可以看到,线程数越多,效率越低。这是因为本实验并非所有工作都随 CPU 线程数增加而加速:GPU SpMV 时间、CPU-GPU 数据传输时间、kernel 同步时间和部分串行控制逻辑都是固定开销。
6.6 总运行时间与耗时构成分析
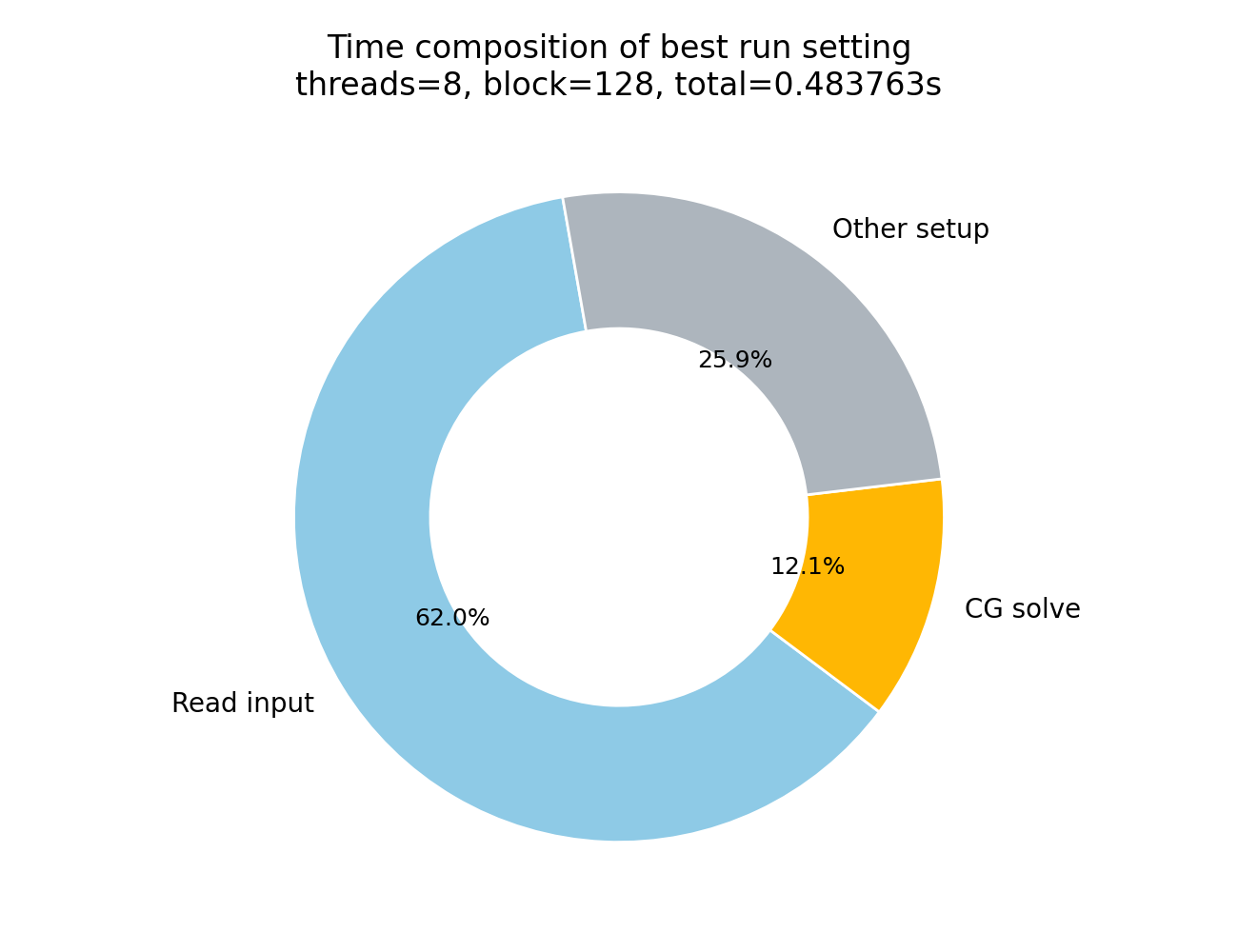
从总运行时间看,最佳组合仍为:
CPU threads = 8
GPU block size = 128
avg total time = 0.483763 s不过,总运行时间的变化幅度小于 CG 时间的变化幅度。原因是总时间中包含输入文件读取和设备内存初始化等一次性开销。由统计数据可知,在最佳组合下:
read time = 0.299901 s
CG time = 0.058565 s
total time = 0.483763 s其中,读取输入文件约占总时间的 62.0%,CG 求解阶段约占总时间的 12.1%,其余时间主要来自设备内存分配、CSR 数据复制和程序初始化等开销。因此,在总时间中,I/O 和初始化开销占比较高,会掩盖一部分计算阶段的加速效果。
这说明如果分析算法求解性能,应重点关注 CG time 和 SpMV time;如果分析完整程序的用户感知运行时间,则应关注 total time。
6.7 综合分析
本实验结果可以总结为以下几点:
- 正确性方面:所有组合均在 12 次迭代后收敛,相对残差为
5.332733e-07,满足1e-6阈值; - CPU 线程数方面:从 1 线程增加到 8 线程有明显加速,但 16 线程没有继续提升;
- GPU block size 方面:block size = 128 在本实验矩阵和 kernel 实现下表现最好;
- 总时间方面:文件读取和设备初始化开销占比较高,因此总时间加速幅度小于 CG 时间;
- 异构瓶颈方面:本实验只将
SpMV放到 GPU,点积和向量更新仍在 CPU,且每轮迭代需要传输p和Ap,因此加速比受到数据传输和同步开销限制。
如果进一步优化,可以考虑将 p、Ap、x、r 等向量长期保留在 GPU,并将点积 reduction 和向量更新也移植到 GPU,以减少每轮迭代中的主机与设备数据传输。
七、个人总结
通过本次实验,我对异构并行程序的性能特点有了更直接的认识。相比实验二的 CPU 多线程和实验三的 MPI 多进程,本次实验不仅要考虑“如何把计算划分出去”,还要考虑 CPU 与 GPU 之间的数据传输和同步开销。如果只把一个局部计算 kernel 放到 GPU 上,而其他部分仍保留在 CPU 上,那么 GPU kernel 本身即使很快,整体程序也未必能获得线性加速。
本次实验中,SpMV 被放到 GPU 上执行,CPU 端使用 OpenMP 并行点积和向量更新。实验结果显示,8 个 CPU 线程配合 block size = 128 时效果最好,平均 CG 时间为 0.058565 s,相对于 1 线程、block size = 128 的基准组合,加速比约为 1.72。继续增加到 16 线程后,性能没有继续提升,说明线程调度、内存访问和数据传输等开销已经开始限制加速效果。
本实验也让我认识到,异构并行优化不能只看某一个 kernel 的运行时间,还要从完整算法的数据流出发分析。对于 CG 这类迭代算法,如果每轮都在 CPU 和 GPU 之间搬运向量,数据传输会成为明显开销。后续若继续优化,我会优先尝试把点积、向量更新和残差判断也放到 GPU 上,让主要向量数据尽量常驻设备端,从而减少 CPU-GPU 往返传输。
总体而言,本次实验完成了 HIP 版本 CSR SpMV 的实现,并通过控制 CPU 线程数和 GPU block size 进行了系统对照实验。实验结果说明,异构并行能够提升稀疏线性方程组求解效率,但合理的任务划分、数据驻留策略和 kernel 参数选择同样重要。

