基于 MPI 的 CSR 稀疏矩阵 CG 并行求解与多节点性能分析
这篇文章由《并行计算》课程实验报告整理而来,保留实验思路、实现方法、核心代码、性能数据和图表,便于后续复盘。
一、实验名称与内容
1.1 实验名称
基于 MPI 的 CSR 稀疏矩阵共轭梯度法并行实现与多节点性能分析。
1.2 实验内容
本实验针对实验二中的稀疏线性方程组求解问题,将共享内存 Pthread 程序扩展为基于 MPI 的多进程并行程序。实验对象仍为对称正定稀疏线性方程组:
A x = b其中矩阵 A 采用 CSR(Compressed Sparse Row,压缩稀疏行)格式存储,求解算法采用共轭梯度法(Conjugate Gradient, CG)。本次实验的核心任务包括:
- 设计并实现 MPI 版本的 CG 求解程序;
- 将矩阵按行连续分块,使每个 MPI 进程只保存自己的局部 CSR 行块;
- 在每轮迭代中完成局部稀疏矩阵向量乘
SpMV、局部点积和向量更新; - 使用
MPI_Allreduce汇总全局点积结果; - 在单节点和多节点配置下重复运行程序,统计平均运行时间、加速比和并行效率;
- 分析进程数、节点数、通信开销、I/O 开销和负载划分方式对性能的影响。
本实验沿用了实验二中对 CG、CSR 和大规模输入数据的设置,但并行模型从“单节点共享内存多线程”变为“多进程消息传递”。因此,本实验不仅考察计算阶段的并行加速,还考察跨进程通信、跨节点调度和分布式数据读取带来的影响。
二、实验环境的配置参数
本实验运行在课程提供的高性能计算集群上。按照实验报告对“环境参数”的要求,本节只保留与硬件平台直接相关的信息,即处理器、内存、互联与加速器等参数。
| 项目 | 参数 |
|---|---|
| 集群结构 | 1 个管理节点 + 7 个计算节点 |
| CPU 型号 | 2 x Intel(R) Xeon(R) Gold 5218 |
| CPU 其他参数 | 实验指导书未给出主频、核数、缓存等更细参数,本报告不做臆测 |
| GPU 型号与参数 | 本次实验未使用 GPU;现有材料未给出 GPU 相关配置 |
| 内存容量 | 256 GB |
| 内存带宽 | 实验指导书未给出实测或标称带宽参数 |
| 互联网络参数 | 实验指导书未给出网络型号、带宽与延迟参数 |
需要说明的是,实验指导书和现有材料对 CPU 主频、核数、缓存、内存带宽以及节点间互联网络参数没有提供明确数据,因此本节仅保留可确认的信息,不补写无法核实的配置。软件环境、输入规模和程序组织放到后文更合适的位置说明。
三、实验题目问题分析
3.1 问题类型分析
本题要求求解大规模稀疏线性方程组 Ax = b,属于典型的科学计算数值问题。从计算特征看,它具有以下特点:
- 问题规模大:当前实验输入规模达到
n = 5,000,000、nnz = 34,999,988; - 数据稀疏:矩阵绝大多数元素为 0,适合采用压缩存储格式;
- 迭代求解:程序不是一次性直接求逆,而是通过反复迭代逼近解向量;
- 访存占主导:核心
SpMV需要频繁访问values、row_ptr、col_idx和向量数据,因此这是一个明显带有内存访问特征的问题; - 需要全局标量:每轮迭代中的点积结果会影响后续更新,因此并行后仍然存在全局同步需求。
因此,本题既不是完全计算密集型问题,也不是完全通信密集型问题,而是一个“局部计算量较大、但每轮又需要全局规约”的分布式稀疏迭代求解问题。
3.2 可并行性分析
从程序结构看,本题具有比较清晰的数据并行特征。对本次实现而言,一轮迭代中需要重点处理的部分为:
SpMV:稀疏矩阵向量乘;- 点积规约:
p · Ap和r · r; - 向量更新:
x、r、p的逐元素更新; - MPI 通信:边界向量交换与全局规约。
其中,SpMV 和向量更新都可以按行或按下标划分给不同进程,天然具有并行性;而点积虽然也可以先做局部部分和,但最终必须通过全局规约得到统一标量。因此,本题的并行难点不在于“能不能并行”,而在于:
- 如何划分矩阵和向量,使每个进程的工作量尽量均衡;
- 如何在保证数据正确性的前提下减少通信;
- 如何控制全局规约对扩展性的影响。
3.3 可选并行化方案
围绕上述问题,本题至少可以考虑以下几类并行化方案。
第一类方案是按行连续分块。将矩阵 A 的连续若干行分给每个进程,每个进程只保存自己的局部 CSR 行块。这种方案实现简单、数据结构清晰,而且连续行块通常有较好的局部性,是 MPI 稀疏矩阵程序最常见的方案。
第二类方案是非连续划分,例如循环划分。也就是让进程按 rank, rank + P, rank + 2P, ... 的方式负责多段分散行。这种方式在某些负载不均问题中可能有优势,但会破坏连续存储和局部性,也会让局部 CSR 的组织更复杂。
第三类方案是“完整向量复制”与“边界交换”两种通信策略的选择。
- 如果所有进程都保存完整向量,那么局部
SpMV访问最方便,但会占用更多内存,并可能需要更频繁的全量同步; - 如果每个进程只保存局部向量片段,则需要在迭代中交换边界数据,但内存占用更小,更符合分布式存储思路。
第四类方案是并行模型的选择。
- 共享内存环境可以采用 Pthread 或 OpenMP;
- 分布式环境更适合采用 MPI;
- 若节点内核心很多,也可以采用 MPI+线程的混合并行。
3.4 本实验方案选择
结合实验指导书要求和当前输入矩阵的结构特征,本实验最终采用 MPI 多进程、连续行块划分、本地 CSR 存储、边界 halo 交换和 MPI_Allreduce 全局规约的方案。
选择这套方案主要有三点原因:
- 当前矩阵是带状稀疏矩阵,跨行块依赖主要集中在边界附近,因此边界交换比全量向量复制更合适;
- 连续行块划分便于构造本地
row_ptr、values和col_idx,实现难度低,适合作为实验报告中的主方案; - 实验目标不仅是“跑通程序”,还要观察进程数、节点数和通信开销对性能的影响,因此 MPI 分布式实现更符合实验三的重点。
四、方案设计
4.1 并行方法总体流程
本节重点给出并行方法本身的设计思路。图 4-1 到图 4-3 分别从“数据如何分布”“进程之间如何通信”和“程序如何执行”三个角度说明本实验采用的 MPI 并行方法。
图 4-1 展示了从全局稀疏矩阵到各进程本地 CSR 行块的划分方式。它强调的是本实验的核心数据分布:矩阵按连续行块切分,每个 rank 只保存自己的 values、row_ptr 和 col_idx 片段。
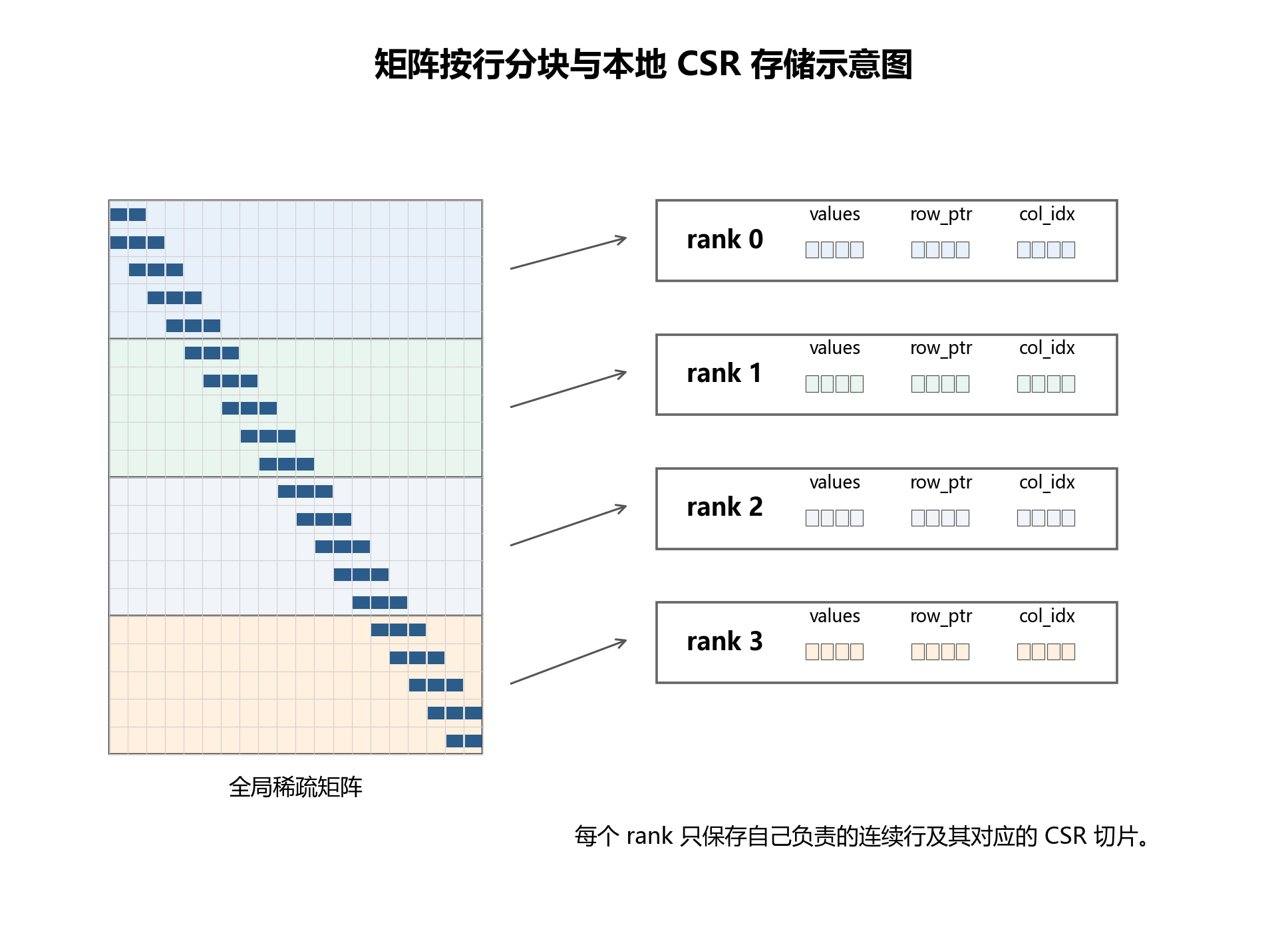
图 4-2 展示了 MPI 并行方法框图。图中可以看出,并行方法由三部分组成:按连续行块分配本地 CSR,进程之间交换边界 p 值,所有进程通过 MPI_Allreduce 汇总点积标量。该图直接对应当前 sparse.cpp 中的实现思路。
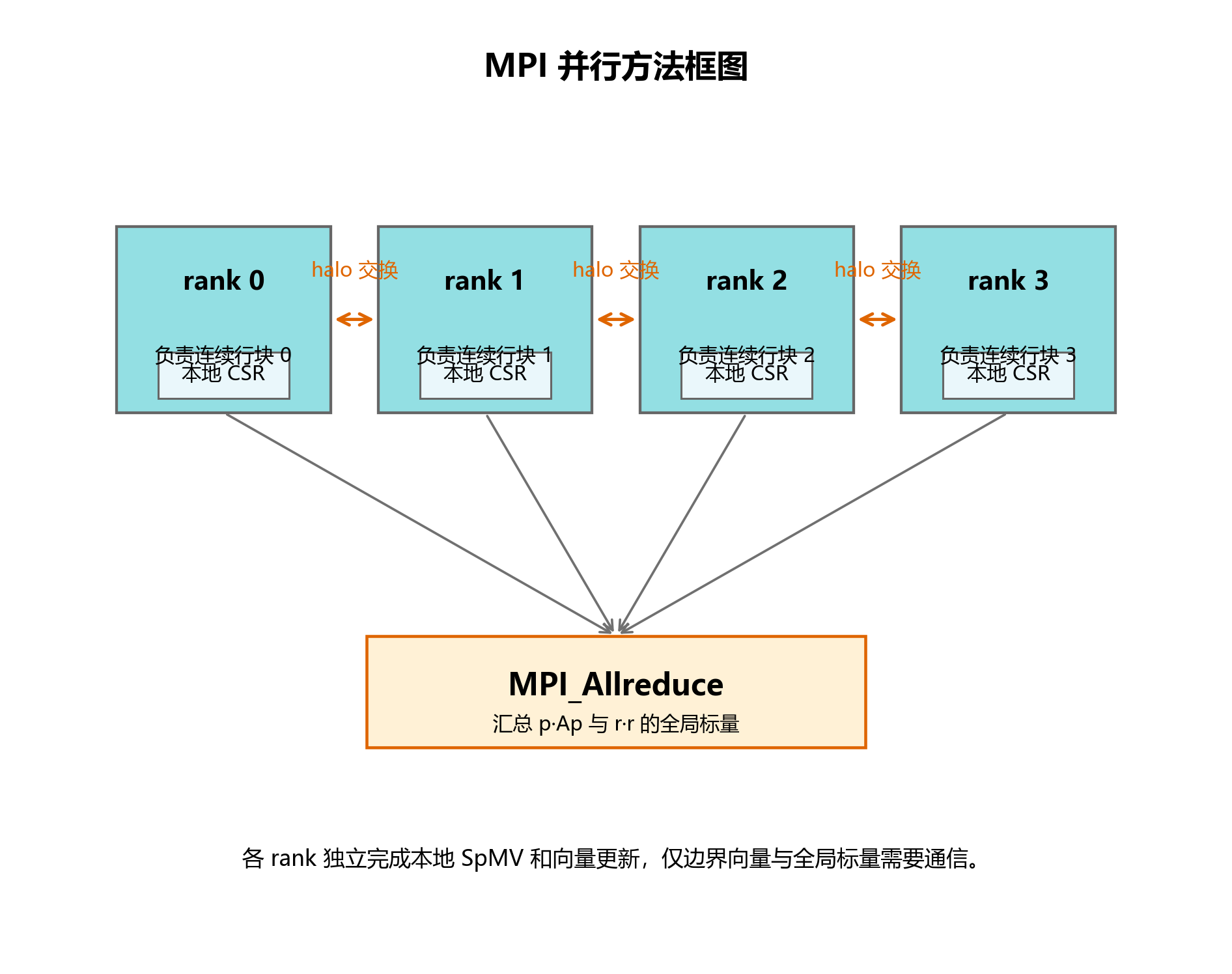
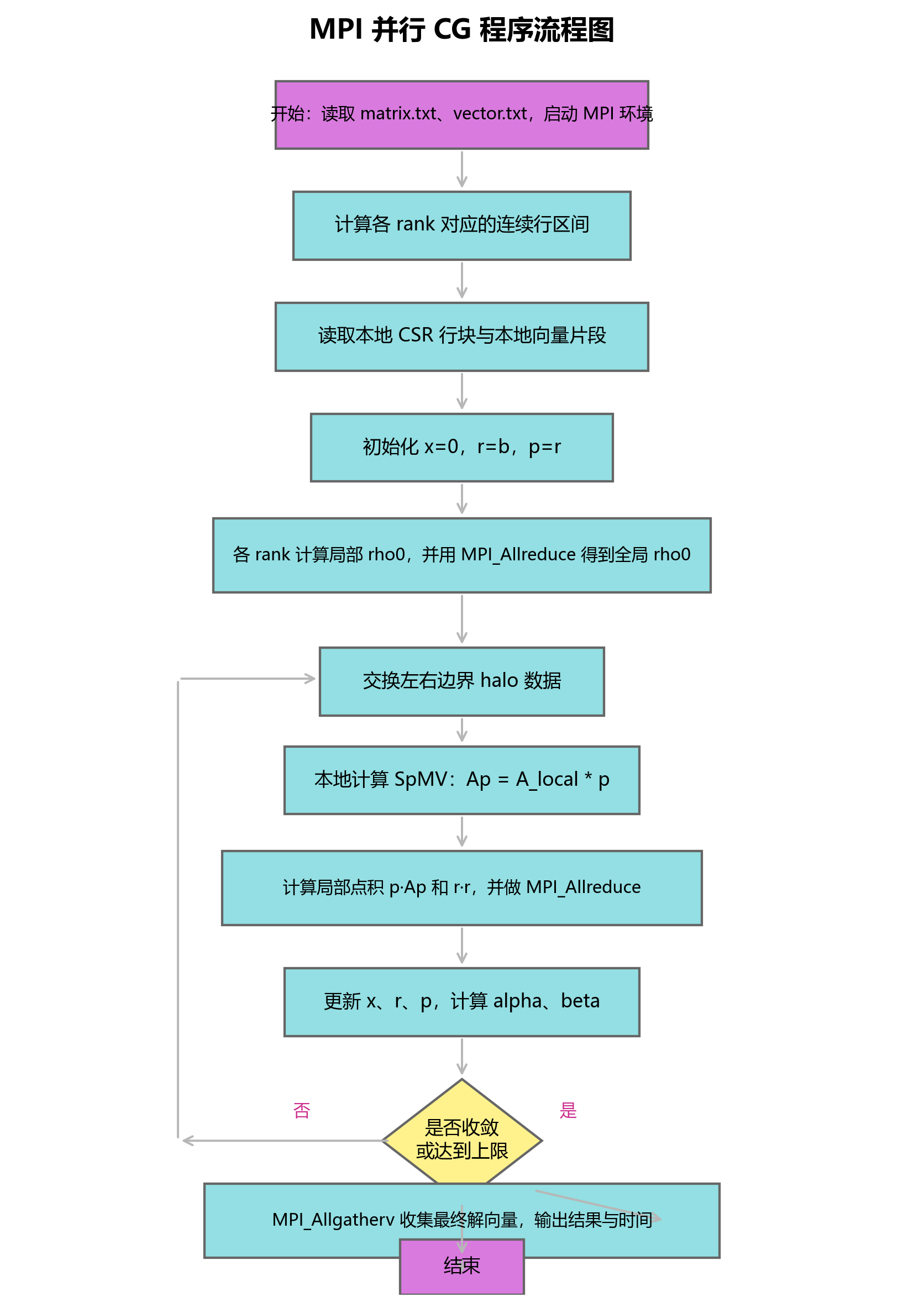
图 4-3 展示了 MPI 版本求解器的一轮主要流程。与前面的框图相比,流程图更强调程序执行顺序:先读取局部数据,再循环执行边界通信、本地计算、全局规约和向量更新,最后收集结果。
MPI 程序整体流程如下:
MPI_Init
获取 rank 和进程总数 P
读取矩阵维度 n 和非零元个数 nnz
根据 rank 计算本进程负责的行区间 [start, end)
读取本地 CSR 行块和本地右端向量 b_local
初始化 x_local = 0, r_local = b_local, p_local = r_local
计算初始全局残差 rho0 = Allreduce(r_local · r_local)
for iter = 0 .. max_iter - 1:
与相邻进程交换 p_local 的边界数据
使用本地 CSR 行块计算 Ap_local = A_local * p
计算局部 pAp_local = p_local · Ap_local
pAp = Allreduce(pAp_local)
alpha = rho0 / pAp
更新 x_local 和 r_local
计算 rho_new_local = r_local · r_local
rho_new = Allreduce(rho_new_local)
若相对残差满足阈值则退出
beta = rho_new / rho0
更新 p_local
rho0 = rho_new
Allgatherv 收集最终解向量 x
输出校验和、前 10 个解分量和运行时间
MPI_Finalize4.2 并行算法伪代码
MPI 版本首先要解决的是“每个进程算哪些行、哪些数据需要交换、每轮迭代如何同步”。本实验采用按连续行块划分矩阵与向量,并在每一轮迭代中执行“边界交换 + 本地 SpMV + 全局规约 + 向量更新”的模式。
伪代码如下:
1. 串行 CG 算法伪代码
读入 CSR 矩阵 A 和向量 b
初始化 x = 0
初始化 r = b
初始化 p = r
rho0 = dot(r, r)
如果 sqrt(rho0) < tol:
结束
for iter = 0 .. max_iter-1:
Ap = SpMV(A, p)
pAp = dot(p, Ap)
如果 |pAp| 很小:
跳出循环
alpha = rho0 / pAp
for i = 0 .. n-1:
x[i] = x[i] + alpha * p[i]
r[i] = r[i] - alpha * Ap[i]
rho_new = dot(r, r)
res_norm = sqrt(rho_new)
如果 res_norm / sqrt(rho0) < tol:
跳出循环
beta = rho_new / rho0
for i = 0 .. n-1:
p[i] = r[i] + beta * p[i]
rho0 = rho_new
输出结果 x2. 并行主进程流程伪代码
MPI_Init
rank = 当前进程号
num_procs = 总进程数
读入矩阵维数 n 和非零元个数 nnz
根据 rank 和 num_procs 计算本进程行区间 [row_start, row_end)
local_n = row_end - row_start
读取本地 CSR 行块 A_local
读取本地向量片段 b_local
分配共享数组 x_local, r_local, p_local, Ap_local
分配 halo 缓冲 left_halo, right_halo
初始化:
for i = 0 .. local_n-1:
x_local[i] = 0
r_local[i] = b_local[i]
p_local[i] = r_local[i]
rho0 = AllReduce(dot(r_local, r_local))
res_norm = sqrt(rho0)
for iter = 0 .. max_iter-1:
// halo 交换
与左邻居发送/接收 p_local 左边界
与右邻居发送/接收 p_local 右边界
// 本地 SpMV
for i = 0 .. local_n-1:
Ap_local[i] = 0
for j = row_ptr_local[i] .. row_ptr_local[i+1]-1:
col = col_idx_local[j]
根据列号从本地或 halo 缓冲获取 p 值
Ap_local[i] += values_local[j] * p值
// 全局规约:计算 alpha
local_pAp = dot(p_local, Ap_local)
pAp = AllReduce(local_pAp)
如果 |pAp| 很小:
跳出循环
alpha = rho0 / pAp
// 向量更新
for i = 0 .. local_n-1:
x_local[i] = x_local[i] + alpha * p_local[i]
r_local[i] = r_local[i] - alpha * Ap_local[i]
// 全局规约:计算 beta
local_rho_new = dot(r_local, r_local)
rho_new = AllReduce(local_rho_new)
res_norm_new = sqrt(rho_new)
如果 res_norm_new / res_norm < tol:
跳出循环
beta = rho_new / rho0
// 搜索方向更新
for i = 0 .. local_n-1:
p_local[i] = r_local[i] + beta * p_local[i]
rho0 = rho_new
// 结果收集
x = AllGatherV(x_local)
由 rank=0 输出:
收敛迭代次数
残差范数和相对残差
解向量前几项
校验和
运行时间
释放分配的内存
MPI_Finalize上述伪代码对应的总体思路为:先按行分块进行数据分布(初始化阶段),再在每轮迭代中通过 halo 交换、本地 SpMV、全局规约和向量更新构成完整的共轭梯度步骤。对于当前带状稀疏矩阵,halo 交换的通信量有限,因此 MPI_Allreduce 成为扩展性的主要限制。
4.3 正确性验证思路
程序在 rank=0 输出:
- 收敛迭代次数;
- 残差范数和相对残差;
- 解向量前 10 项;
- 解向量校验和
x_checksum; - 读入时间、CG 时间、收集时间和总运行时间。
实验中以串行程序作为基线,并使用 MPI 程序输出的收敛信息和校验信息辅助确认结果没有明显错误。由于本报告主要分析 time 命令得到的 wall time,后续性能统计以 real 时间为准。
五、实现方法
5.1 输入数据与文件组织
本实验使用的大规模输入数据如下:
| 参数 | 数值 |
|---|---|
矩阵维度 n | 5,000,000 |
非零元个数 nnz | 34,999,988 |
| 矩阵类型 | 对称正定带状稀疏矩阵 |
| 带宽参数 | 3 |
| 最大迭代次数 | 1000 |
| 收敛阈值 | 1e-6 |
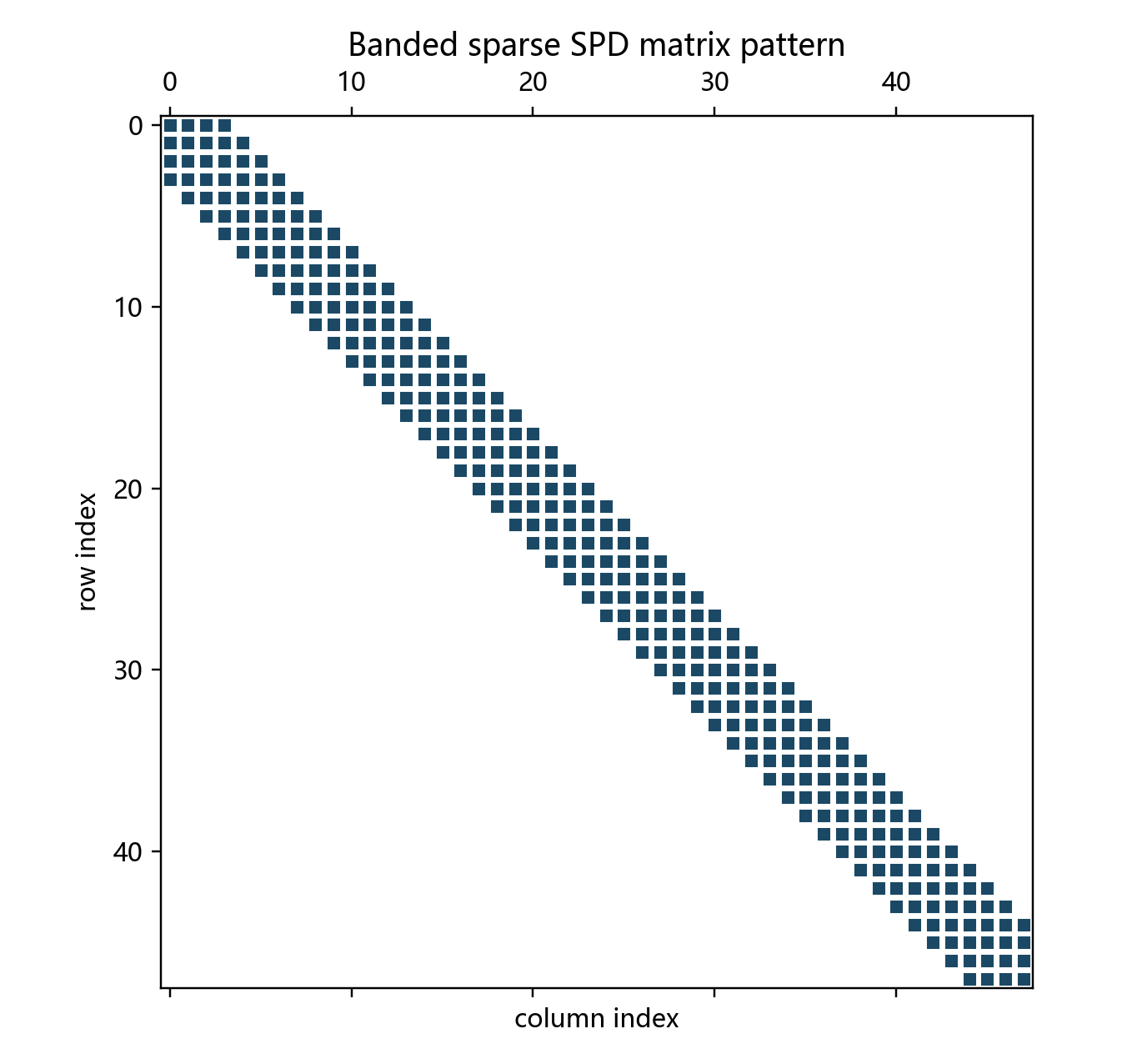
矩阵生成程序采用带状结构:每一行最多包含主对角线及左右各 3 个邻接位置,因此内部行大约有 7 个非零元,边界行略少。这一结构既适合 CSR 压缩存储,也使得按行分块后跨进程依赖主要集中在局部边界附近。
图 5-1 给出带状稀疏矩阵的非零结构示意。实际矩阵规模远大于图中示例,但非零元分布模式一致,因此这张图主要用于说明为什么该问题适合按相邻边界进行通信。
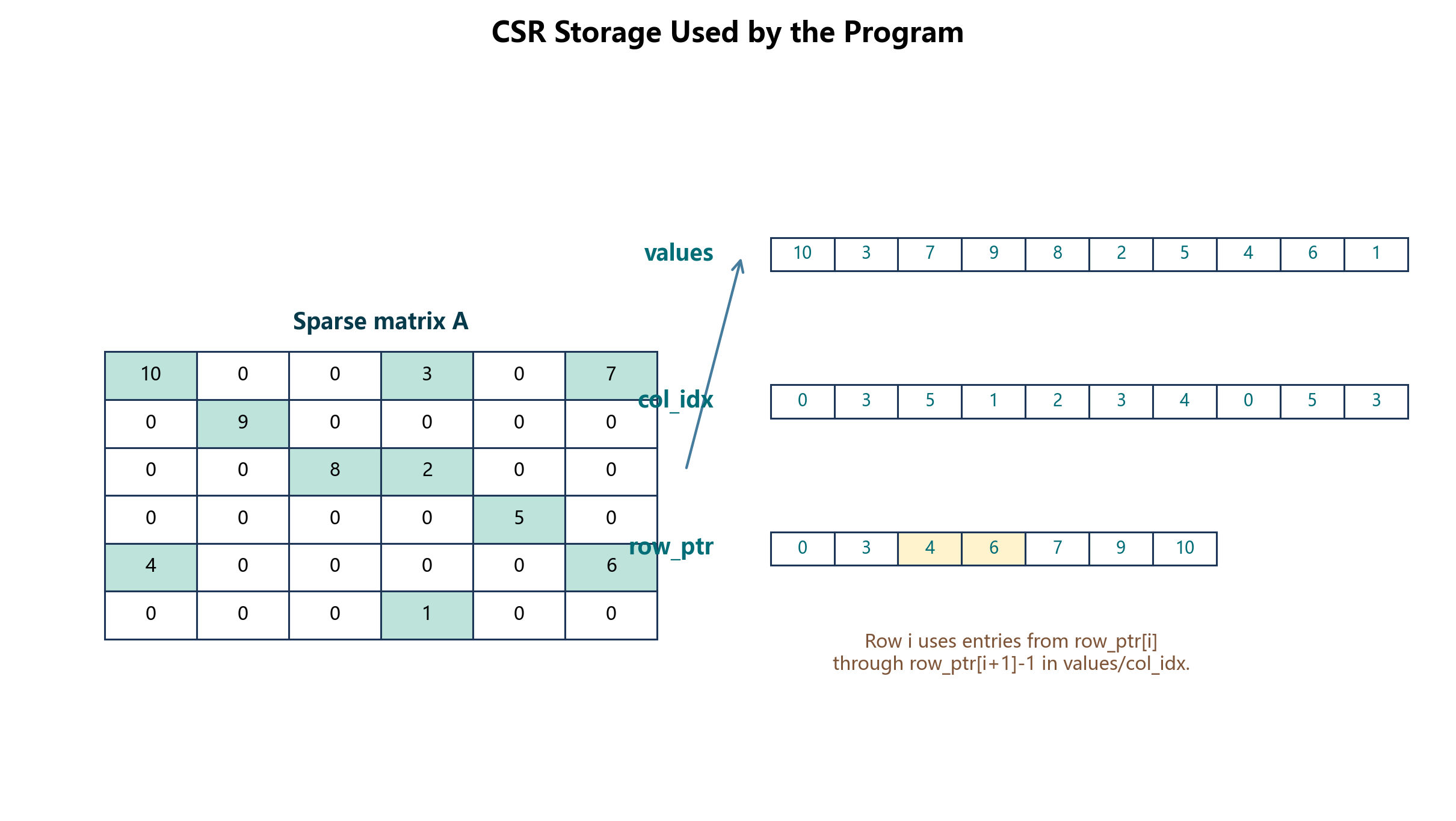
为了更直观地说明本地 CSR 行块是如何从全局矩阵中截取出来的,图 5-2 给出了 values、col_idx 和 row_ptr 三个数组之间的对应关系。后续 MPI 按行分块时,本质上就是让每个进程只保留 row_ptr 中一段连续行区间及其对应的 values、col_idx。
从文件组织上看,核心实现集中在 sparse.cpp 中,输入文件包括矩阵文件 matrix.txt 和右端向量文件 vector.txt。程序运行时,每个进程只构造本地 CSR 数据结构,而不在内存中保留完整矩阵。
5.2 计算环境与编程实现方案
程序运行在课程提供的集群环境上,采用 C++ + MPI 的实现方式。MPI 负责进程创建、消息传递和全局规约,g++ 负责编译,PBS 脚本负责提交不同节点数与 ppn 配置的批处理作业。代码入口是 main 函数,实际执行时先通过 MPI_Init、MPI_Comm_rank 和 MPI_Comm_size 获取 rank 与 num_procs,再调用 compute_range 划分本地行区间,随后用 FastScanner 读取本地 CSR 与向量片段,最后调用 cg_mpi 完成迭代求解,并在 rank=0 输出统计结果。
在集群上的基本编译与运行流程如下:
mpicxx -O3 -o sparse_mpi sparse.cpp -lm
qsub run.pbs其中 sparse_mpi_1.pbs、sparse_mpi_2.pbs、sparse_mpi_4.pbs 以及 sparse_mpi_n2_ppn8.pbs 这类脚本负责指定节点数、每节点进程数以及 mpirun 的启动方式。它们的结构基本一致:先设置作业名,再加载 MPI 模块,然后进入 $PBS_O_WORKDIR,再用 $PBS_NODEFILE 统计实际进程数 procs,最后执行 time mpirun。例如 sparse_mpi_4.pbs 的写法是:
#PBS -N sparse_mpi_4
#PBS -l nodes=1:ppn=4
#PBS -j oe
NAME="NiuTianhao"
ID="3024244288"
MATRIX_FILE="matrix.txt"
VECTOR_FILE="vector.txt"
if command -v module >/dev/null 2>&1; then
module load mpi
fi
cd $PBS_O_WORKDIR
procs=$(cat $PBS_NODEFILE | wc -l)
time mpirun -np $procs -machinefile $PBS_NODEFILE ./sparse_mpi $MATRIX_FILE $VECTOR_FILE >& run_mpi_4_${PBS_JOBID}.log如果是多节点脚本,比如 sparse_mpi_n4_ppn8.pbs,脚本里会额外写出 Nodes: 4 和 PPN: 8,但核心执行方式还是一样:procs=$(cat $PBS_NODEFILE | wc -l),然后用 time mpirun -np $procs -machinefile $PBS_NODEFILE ./sparse_mpi $MATRIX_FILE $VECTOR_FILE >& ...。这种写法和你的实验结果是一一对应的,也说明后面的运行时间统计其实就是各个 PBS 脚本提交出来的作业输出。
5.3 行块划分实现
MPI 版本首先要解决的是“每个进程算哪些行”。当前程序使用连续行块划分,若 n 不能被进程数整除,则前 extra 个进程各多分 1 行。这样可以保证所有行都被覆盖,并且每个进程的行数最多只相差 1。
// Block row partition: contiguous rows for each rank.
static void compute_range(int n, int num_procs, int rank, int& start, int& end)
{
int base = n / num_procs;
int extra = n % num_procs;
start = rank * base + (rank < extra ? rank : extra);
end = start + base + (rank < extra ? 1 : 0);
}主函数中对所有进程预先计算 recv_counts 和 recv_displs。这两个数组不仅用于确定本进程行区间,也用于最后 MPI_Allgatherv 收集解向量。
int* recv_counts = (int*)malloc(num_procs * sizeof(int));
int* recv_displs = (int*)malloc(num_procs * sizeof(int));
for (int r = 0; r < num_procs; r++)
{
int start = 0, end = 0;
compute_range(n, num_procs, r, start, end);
recv_counts[r] = end - start;
recv_displs[r] = start;
}
int row_start = recv_displs[rank];
int local_n = recv_counts[rank];连续行块划分的优点是实现简单、局部 CSR 数据连续、最终收集时位移数组容易构造;缺点是如果矩阵每行非零元数量差异很大,可能造成负载不均。不过本实验输入是带状矩阵,每行非零元数量接近,因此连续分块是合适选择。
5.4 本地 CSR 行块读取实现
当前输入文件 matrix.txt 较大,完整矩阵约 800 MB。若每个进程都完整读取并保存所有数组,内存和 I/O 压力都会增大。因此程序采用局部读取策略:
- 所有进程先读取矩阵头部
n和nnz; - 根据
rank计算本进程负责的行范围; - 第一次扫描文件,读取
row_ptr中与本地行块相关的偏移; - 根据本地行块偏移计算
local_nnz; - 第二次扫描文件,只读入本地非零元
values_local和col_idx_local; - 右端向量
vector.txt也只读取本地行区间对应的b_local。
下面代码展示了本地 row_ptr 的读取方式。程序先跳过完整 values 段,再只保留本进程行区间 [row_start, row_start + local_n] 对应的 row_ptr。随后用偏移量把本地 row_ptr 归零,使局部 CSR 数组可以从下标 0 开始访问。
row_ptr_local = (int*)malloc((local_n + 1) * sizeof(int));
for (int i = 0; i < nnz; i++)
{
if (!ms.skip_double())
{
printf("[Rank %d] Failed to skip values array\n", rank);
MPI_Abort(MPI_COMM_WORLD, 1);
}
}
for (int i = 0; i <= n; i++)
{
int row_ptr_value = 0;
if (!ms.read_int(row_ptr_value))
{
printf("[Rank %d] Failed to read row_ptr array\n", rank);
MPI_Abort(MPI_COMM_WORLD, 1);
}
if (i >= row_start && i <= row_start + local_n)
{
row_ptr_local[i - row_start] = row_ptr_value;
}
}
int local_nnz = row_ptr_local[local_n] - row_ptr_local[0];
int local_nnz_offset = row_ptr_local[0];
for (int i = local_n; i >= 0; i--)
{
row_ptr_local[i] -= local_nnz_offset;
}接着,程序重新打开矩阵文件,跳过本进程之前的非零元,只读取本地 values_local 和 col_idx_local。这种写法避免每个进程保存完整矩阵。
values_local = (double*)malloc(local_nnz * sizeof(double));
col_idx_local = (int*)malloc(local_nnz * sizeof(int));
b_local = (double*)malloc(local_n * sizeof(double));
mf = fopen(matrix_file, "r");
FastScanner ms2(mf);
int check_n = 0;
int check_nnz = 0;
ms2.read_int(check_n);
ms2.read_int(check_nnz);
for (int i = 0; i < local_nnz_offset; i++)
{
ms2.skip_double();
}
for (int i = 0; i < local_nnz; i++)
{
ms2.read_double(values_local[i]);
}
for (int i = local_nnz_offset + local_nnz; i < nnz; i++)
{
ms2.skip_double();
}
for (int i = 0; i <= n; i++)
{
ms2.skip_int();
}
for (int i = 0; i < local_nnz_offset; i++)
{
ms2.skip_int();
}
for (int i = 0; i < local_nnz; i++)
{
ms2.read_int(col_idx_local[i]);
}右端向量同样只读取本地片段:
FastScanner vs(vf);
for (int i = 0; i < row_start; i++)
{
vs.skip_double();
}
for (int i = 0; i < local_n; i++)
{
vs.read_double(b_local[i]);
}5.5 halo 交换与本地 SpMV 实现
由于矩阵是带宽为 3 的带状矩阵,每个进程本地行块内部的大多数行只依赖本地 p_local。只有靠近行块边界的少量行需要邻居进程的 p 值。程序设置:
const int halo_width = 16;每轮迭代中,进程通过两次 MPI_Sendrecv 完成:
- 向左邻居发送本地左边界,接收右邻居边界;
- 向右邻居发送本地右边界,接收左邻居边界。
虽然当前矩阵带宽为 3,halo_width=16 略大于实际需要,但仍然远小于完整向量长度,通信量非常小。这样做的优点是逻辑简单,并为稍大带宽的输入留有余量。
int left_rank = (rank > 0) ? (rank - 1) : MPI_PROC_NULL;
int right_rank = (rank + 1 < num_procs) ? (rank + 1) : MPI_PROC_NULL;
int send_left = (local_n < halo_width) ? local_n : halo_width;
int send_right = send_left;
MPI_Sendrecv(p_local,
send_left,
MPI_DOUBLE,
left_rank,
100,
right_halo,
right_count,
MPI_DOUBLE,
right_rank,
100,
comm,
MPI_STATUS_IGNORE);
MPI_Sendrecv(p_local + local_n - send_right,
send_right,
MPI_DOUBLE,
right_rank,
101,
left_halo,
left_count,
MPI_DOUBLE,
left_rank,
101,
comm,
MPI_STATUS_IGNORE);halo 数据到达后,本地 SpMV 根据列号判断所需的 p 值来自本地、左 halo 还是右 halo。下面这段循环是 MPI 版本中最核心的本地计算部分。
for (int i = 0; i < local_n; i++)
{
Ap_local[i] = 0.0;
for (int j = row_ptr_local[i]; j < row_ptr_local[i + 1]; j++)
{
int col = col_idx_local[j];
double pv = 0.0;
if (col >= row_start && col < row_end)
{
pv = p_local[col - row_start];
}
else if (col < row_start && col >= row_start - left_count)
{
pv = left_halo[col - (row_start - left_count)];
}
else if (col >= row_end && col < row_end + right_count)
{
pv = right_halo[col - row_end];
}
else
{
printf("[Rank %d] Column %d is outside the halo range for row %d\n",
rank, col, row_start + i);
MPI_Abort(comm, 2);
}
Ap_local[i] += values_local[j] * pv;
}
}5.6 全局规约与向量更新实现
本程序中的两个关键标量都依赖全局点积。每个进程先计算自己的局部和:
pAp_local = sum(p_local[i] * Ap_local[i])
rho_local = sum(r_local[i] * r_local[i])然后通过:
MPI_Allreduce(&pAp_local, &pAp, 1, MPI_DOUBLE, MPI_SUM, comm);
MPI_Allreduce(&rho_new_local, &rho_new, 1, MPI_DOUBLE, MPI_SUM, comm);得到全局结果。MPI_Allreduce 保证所有进程都拿到相同的标量,因此后续 alpha、beta 更新保持一致。
double pAp_local = 0.0;
for (int i = 0; i < local_n; i++)
{
pAp_local += p_local[i] * Ap_local[i];
}
double pAp = 0.0;
MPI_Allreduce(&pAp_local, &pAp, 1, MPI_DOUBLE, MPI_SUM, comm);
if (fabs(pAp) < 1e-10)
{
break;
}
double alpha = rho0 / pAp;
double rho_new_local = 0.0;
for (int i = 0; i < local_n; i++)
{
x_local[i] += alpha * p_local[i];
r_local[i] -= alpha * Ap_local[i];
rho_new_local += r_local[i] * r_local[i];
}
double rho_new = 0.0;
MPI_Allreduce(&rho_new_local, &rho_new, 1, MPI_DOUBLE, MPI_SUM, comm);
double res_norm = sqrt(rho_new);
if (res_norm / initial_res_norm < tol)
{
MPI_Allgatherv(x_local, local_n, MPI_DOUBLE,
x, recv_counts, recv_displs, MPI_DOUBLE, comm);
return iter + 1;
}
double beta = rho_new / rho0;
for (int i = 0; i < local_n; i++)
{
p_local[i] = r_local[i] + beta * p_local[i];
}
rho0 = rho_new;5.7 结果收集与正确性验证实现
最终收集解向量的代码如下。因为每个进程的行块长度可能不同,所以这里使用 MPI_Allgatherv 而不是 MPI_Gather。
MPI_Allgatherv(x_local,
local_n,
MPI_DOUBLE,
x,
recv_counts,
recv_displs,
MPI_DOUBLE,
comm);
if (rank == 0)
{
double checksum = 0.0;
for (int i = 0; i < n; i++)
{
checksum += x[i];
}
printf("x_first10 =");
int print_n = (n < 10) ? n : 10;
for (int i = 0; i < print_n; i++)
{
printf(" %.6f", x[i]);
}
printf("\n");
printf("x_checksum = %.6f\n", checksum);
}六、结果分析
6.1 数据统计口径
每个配置重复运行 10 次。报告中的平均时间、标准差、加速比和效率均基于 data.md 中保留的 10 条样本重新计算。
本报告使用两类加速比:
- 单节点 MPI 加速比:以单节点
1进程 MPI 平均时间作为基线; - 多节点同组加速比:以相同节点数下
ppn=1的平均时间作为基线。
计算方式统一采用最直接的定义:
其中, 表示加速比, 表示并行效率, 表示基线平均时间, 表示当前配置平均时间, 表示进程数(多节点时取总进程数,即 )。
此外,为了与串行程序对照,部分分析也给出相对串行平均时间 97.433 s 的倍率。
6.2 串行基线
串行程序 sparse_serial 的 10 次运行统计为:
| 程序 | 平均时间 / s | 标准差 / s | 最小值 / s | 最大值 / s |
|---|---|---|---|---|
sparse_serial | 97.433 | 1.987 | 95.367 | 101.354 |
串行程序仅使用单进程单线程,没有 MPI 初始化、进程通信和并行文件读取开销,因此它是观察 MPI 并行收益时的重要参照。单节点 1 进程 MPI 的平均时间为 104.209 s,比串行基线慢约 6.95%,说明在不增加并行度时,MPI 初始化、局部读取逻辑和程序结构本身会带来额外开销。
6.3 单节点 MPI 性能
单节点配置使用 nodes=1,分别测试 ppn=1/2/4/8/16,对应总进程数也为 1/2/4/8/16。
| 进程数 | 平均时间 / s | 标准差 / s | 加速比 | 并行效率 | 相对串行倍率 |
|---|---|---|---|---|---|
| 1 | 104.209 | 6.775 | 1.000 | 1.000 | 0.935 |
| 2 | 55.464 | 0.332 | 1.879 | 0.939 | 1.757 |
| 4 | 30.938 | 1.728 | 3.368 | 0.842 | 3.149 |
| 8 | 31.659 | 0.158 | 3.292 | 0.411 | 3.078 |
| 16 | 18.162 | 0.189 | 5.738 | 0.359 | 5.365 |
图 6-1 显示了单节点不同进程数的平均运行时间。可以看到,从 1 到 4 进程,运行时间下降非常明显;从 4 到 8 进程反而略有变慢;到 16 进程又进一步下降。
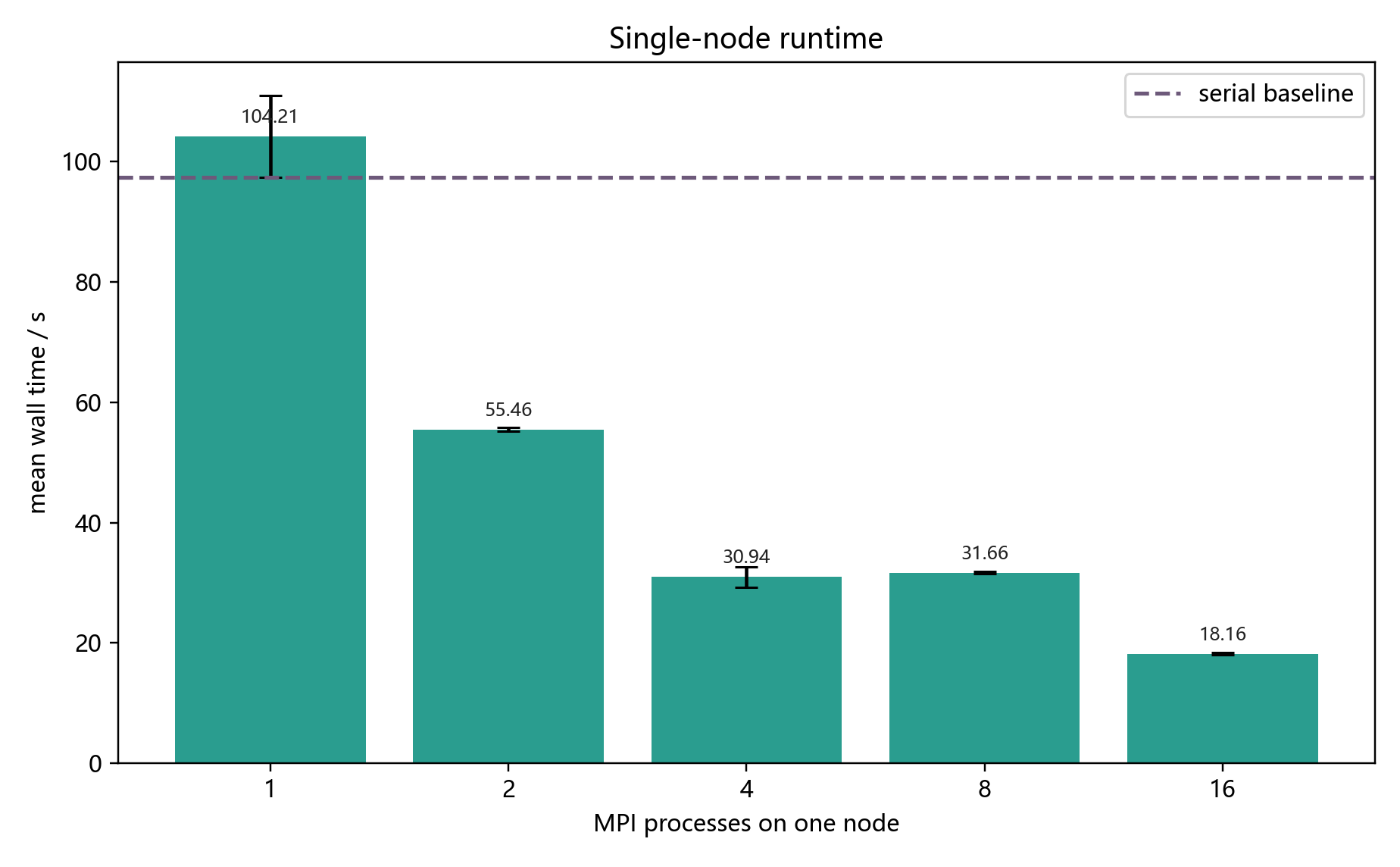
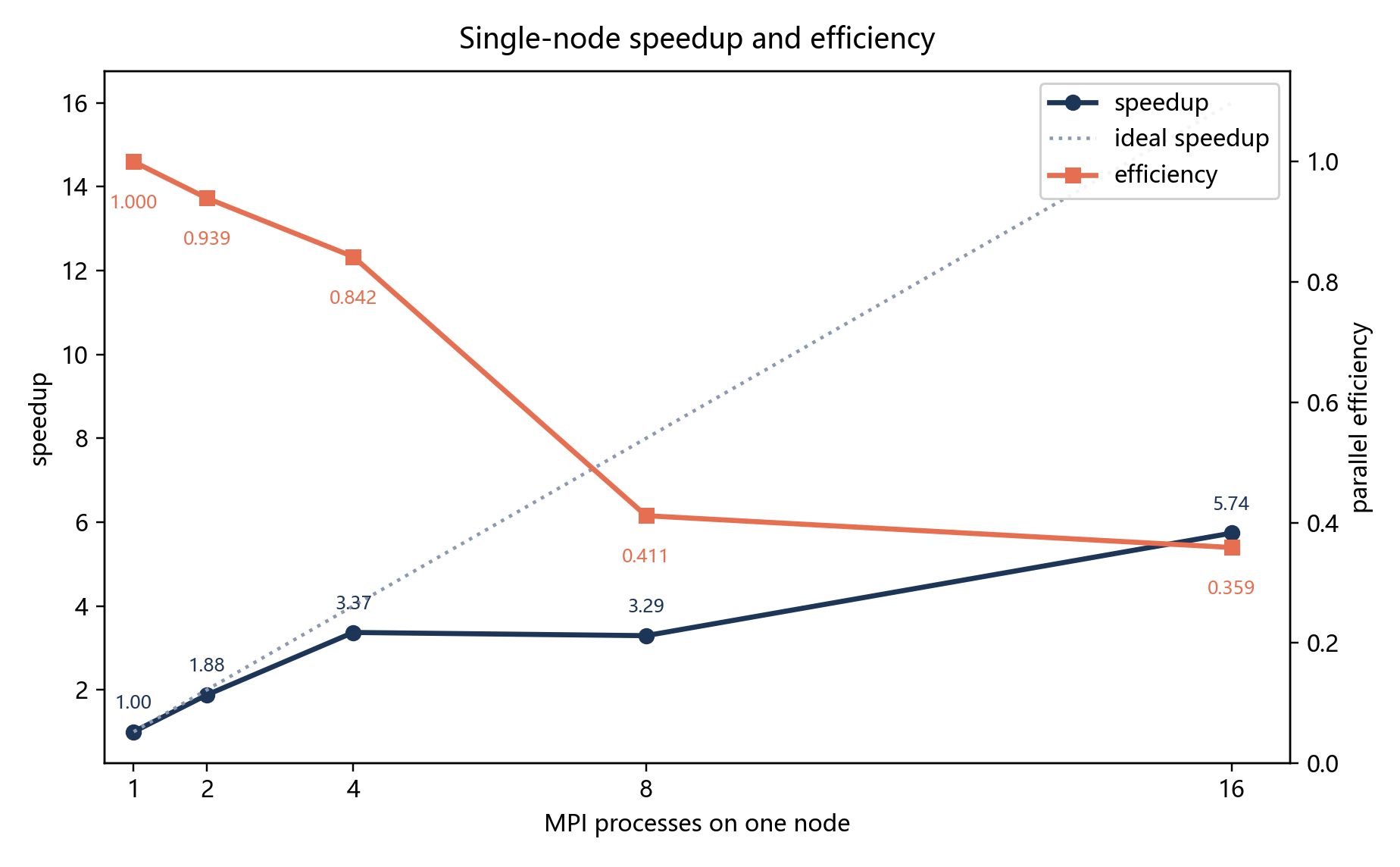
图 6-2 给出单节点加速比和并行效率。2 进程效率达到 0.939,4 进程效率仍有 0.842,说明本问题在小规模进程数下具有较好的并行性。但 8 进程效率降到 0.411,说明此时通信、同步或节点内资源竞争已经明显影响收益。
对单节点结果可以作如下分析:
2和4进程加速效果最好,说明按行分块后SpMV和向量更新的计算量能较好分摊;8进程相对4进程没有继续加速,可能与 MPI 进程间同步、缓存竞争、内存带宽竞争以及作业运行时节点负载有关;16进程显著快于8进程,说明当进程数足够多时,计算量分摊再次压过同步开销,但效率已经下降到0.359;- 单节点 16 进程相对串行程序约有
5.365倍加速,已经明显优于实验二 Pthread 中 16 线程约 4 倍左右的最佳水平,说明当前 MPI 版本的局部数据组织和实现方式在该输入上更适合扩展。
6.4 多节点 MPI 性能
多节点实验测试了 2 节点和 4 节点配置。2 节点测试 ppn=1/2/4/8/16,4 节点测试 ppn=1/2/4/8。nodes=4:ppn=16 需要 64 个进程,提交时受到队列资源上限限制,因此没有有效运行数据。
| 节点数 | 每节点进程数 | 总进程数 | 平均时间 / s | 标准差 / s | 同组加速比 | 同组效率 |
|---|---|---|---|---|---|---|
| 2 | 1 | 2 | 137.267 | 10.016 | 1.000 | 0.500 |
| 2 | 2 | 4 | 33.182 | 0.282 | 4.137 | 1.034 |
| 2 | 4 | 8 | 20.526 | 0.511 | 6.687 | 0.836 |
| 2 | 8 | 16 | 13.112 | 0.344 | 10.469 | 0.654 |
| 2 | 16 | 32 | 12.324 | 0.870 | 11.138 | 0.348 |
| 4 | 1 | 4 | 169.824 | 1.450 | 1.000 | 0.250 |
| 4 | 2 | 8 | 24.587 | 2.082 | 6.907 | 0.863 |
| 4 | 4 | 16 | 15.178 | 1.958 | 11.189 | 0.699 |
| 4 | 8 | 32 | 12.544 | 1.500 | 13.538 | 0.423 |
图 6-3 用折线方式展示了多节点平均运行时间,重点表现两个趋势:第一,ppn=1 时运行时间非常长;第二,当每节点进程数增加到 2、4、8 后,运行时间迅速下降,并在更高进程数附近逐渐进入平台期。
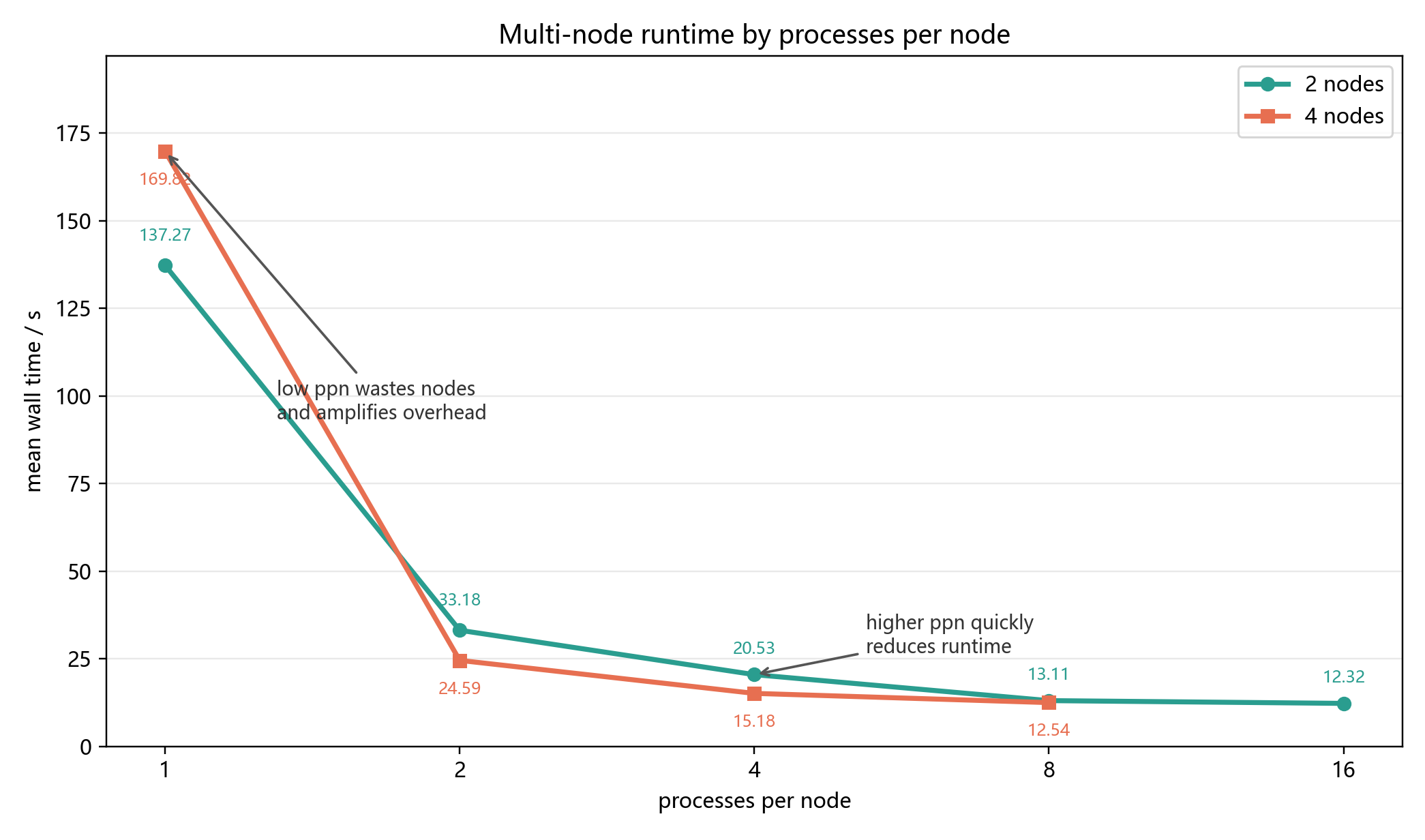
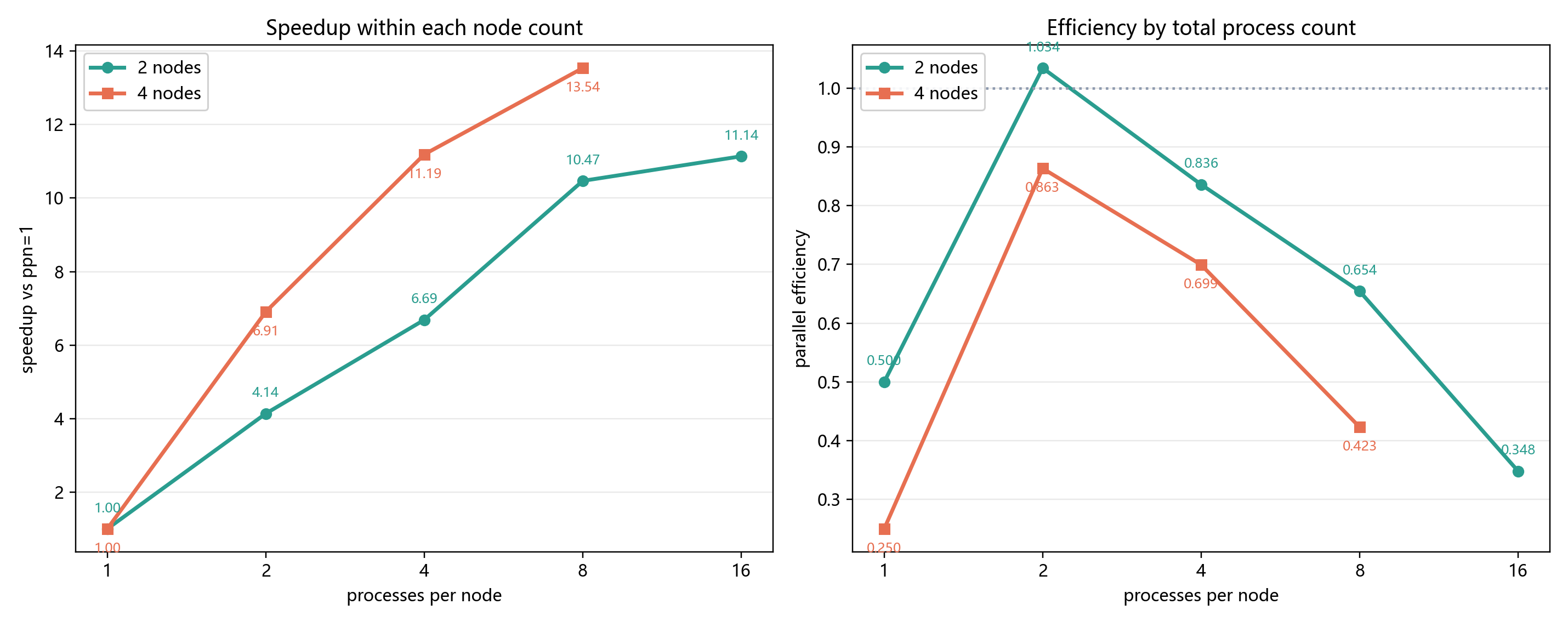
图 6-4 给出同组加速比和效率折线图。这里“同组”指相同节点数下以 ppn=1 为基线。左图用于观察增加每节点进程数后程序能获得多少加速,右图用于观察这种加速是否接近理想比例。
多节点结果有几个值得注意的现象:
nodes=2:ppn=1和nodes=4:ppn=1的时间分别达到137.267 s和169.824 s,比串行程序更慢。这说明只增加节点而每个节点只放 1 个进程时,跨节点调度、启动和 I/O 成本远大于计算收益;- 当每节点进程数增加到 2 或 4 时,运行时间迅速下降。例如 4 节点
ppn=2平均时间为24.587 s,已经明显快于单节点 4 进程; - 2 节点
ppn=16与 4 节点ppn=8都是 32 个总进程,平均时间分别为12.324 s和12.544 s,两者非常接近,说明在总进程数相同且计算量足够分散时,节点布局不是唯一决定因素; - 4 节点
ppn=8的同组效率为0.423,2 节点ppn=16的同组效率为0.348。进程数继续增加后,MPI_Allreduce等全局同步和内存/网络资源竞争逐渐削弱线性扩展能力; - 4 节点
ppn=16无法提交,反映出实际 HPC 实验中资源队列限制也是实验设计的一部分。报告中不能直接外推 64 进程结果,应明确标注该配置无有效数据。
6.5 相同总进程数下的节点布局比较
图 6-5 将单节点、2 节点和 4 节点数据按总进程数放在同一张图中。
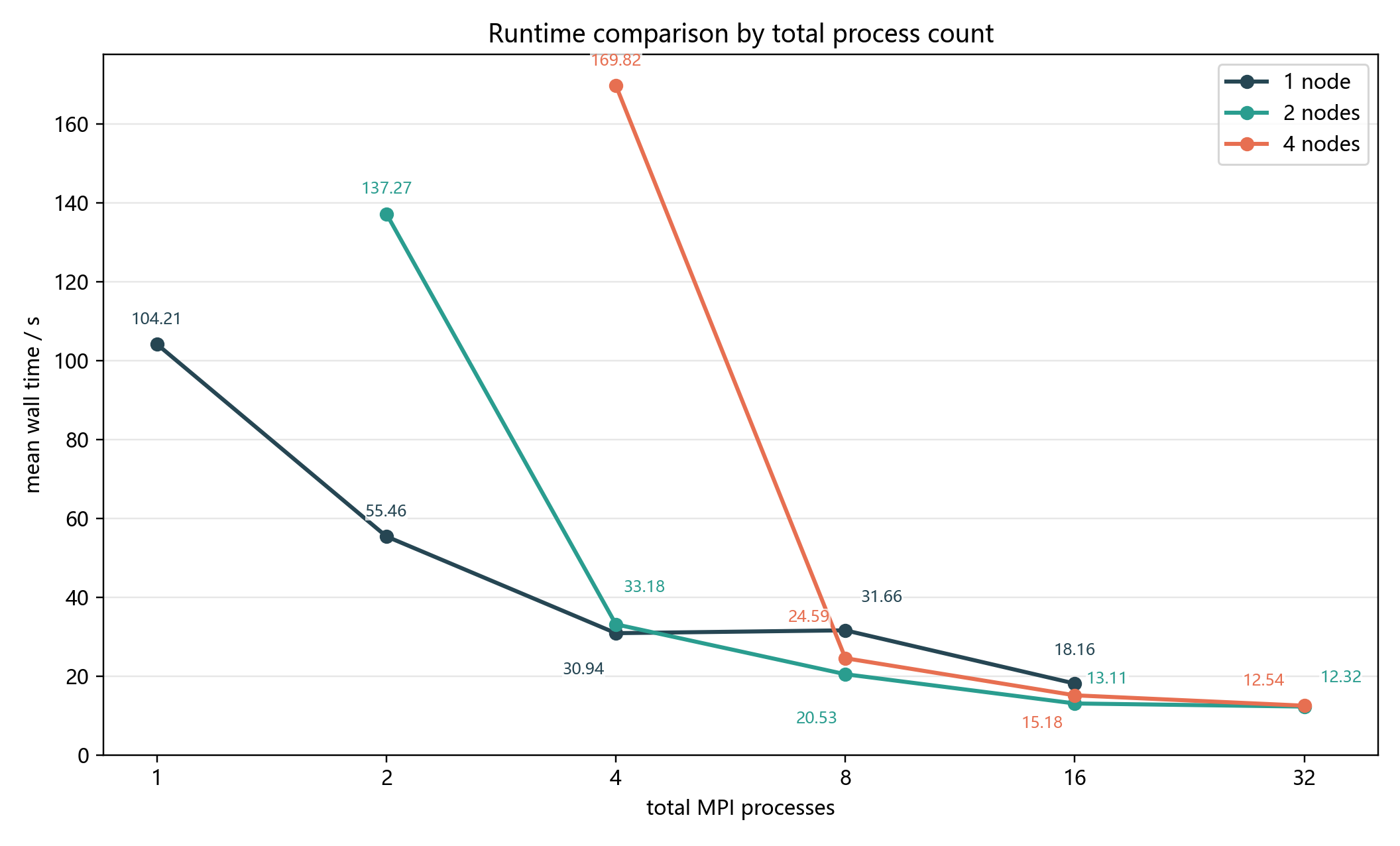
从图中可以看出:
- 总进程数为 4 时,单节点 4 进程为
30.938 s,2 节点ppn=2为33.182 s,4 节点ppn=1为169.824 s。这说明“分散到更多节点”本身不一定带来收益,若每个节点只使用少量进程,I/O 和调度开销会非常突出; - 总进程数为 8 时,4 节点
ppn=2为24.587 s,2 节点ppn=4为20.526 s,单节点 8 进程为31.659 s。2 节点配置在该点表现最好,说明适度跨节点可以缓解单节点资源竞争,但过度分散仍可能拖慢; - 总进程数为 16 时,4 节点
ppn=4为15.178 s,2 节点ppn=8为13.112 s,单节点 16 进程为18.162 s。2 节点ppn=8表现最好; - 总进程数为 32 时,2 节点
ppn=16和 4 节点ppn=8时间几乎相同,说明此时收益已经进入平台期,继续优化需要关注通信规约、I/O 和进程绑定策略。
6.6 运行波动性分析
图 6-6 展示了部分代表配置的运行时间箱线图。
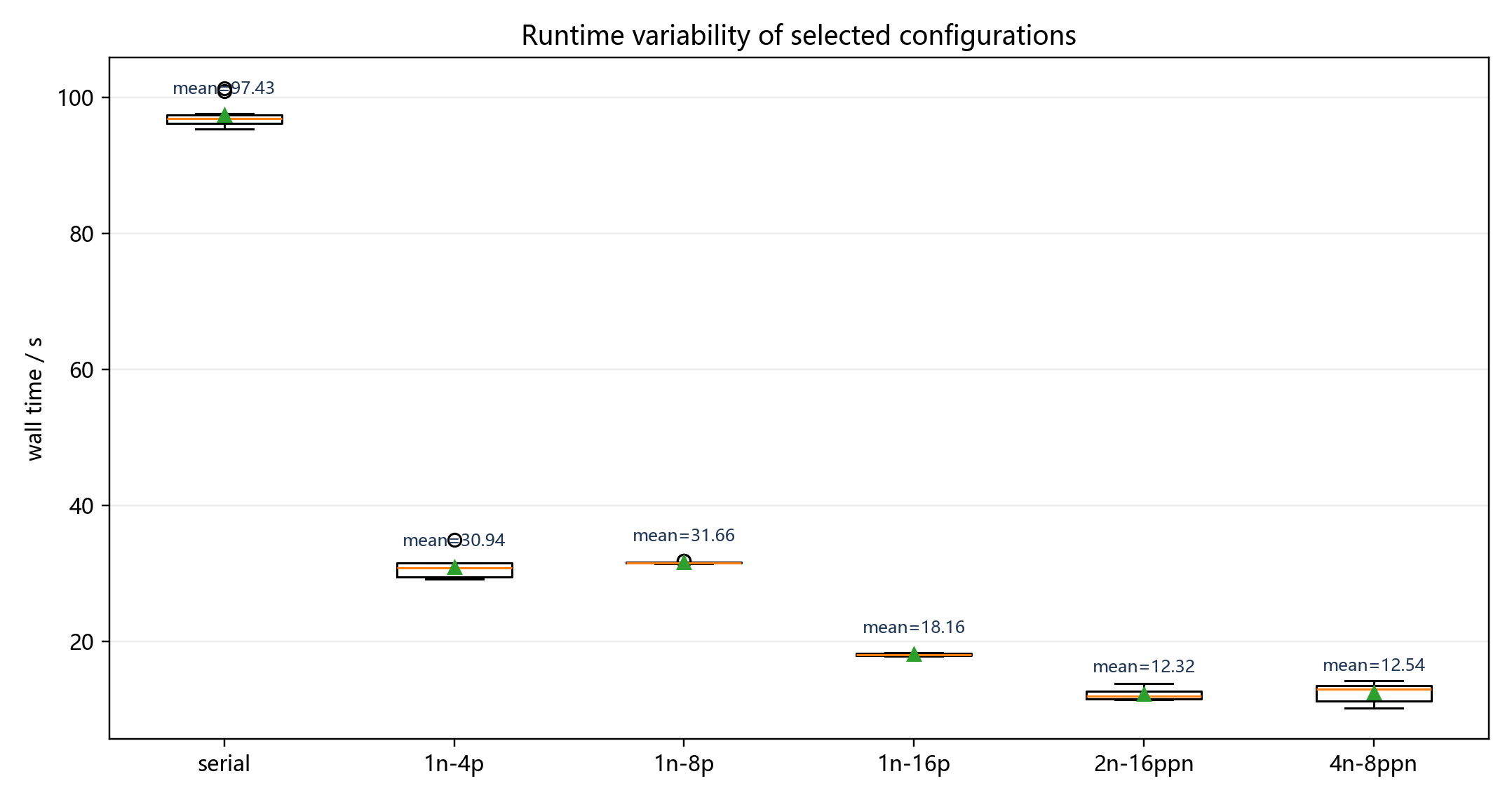
从波动性看:
- 串行程序的时间较稳定,主要分布在
95 s到101 s; - 单节点 1 进程 MPI 波动较大,标准差达到
6.775 s,可能受文件读取、MPI 启动和节点负载影响; - 单节点 8 进程和 16 进程波动很小,说明当进程配置较稳定且运行时间较短时,重复运行结果更集中;
- 多节点 4 节点
ppn=8的波动明显大于 2 节点ppn=16,可能与跨更多节点的调度差异和网络通信差异有关。
因此,报告不能只看单次最快结果,而应采用多次平均值和标准差。当前 10 次样本统计能更可靠地反映程序性能。
6.7 与实验二 Pthread 结果的对照
实验二中使用 Pthread 实现了同一类 CG 稀疏线性方程组求解。根据 lab2 的统计文件,较好的 Pthread 方案在 16 线程时平均时间约为 26.8 s 到 27.0 s,加速比约为 4.0。本实验中:
- 单节点 16 进程 MPI 平均时间为
18.162 s; - 2 节点 16 总进程平均时间为
13.112 s; - 32 总进程最佳平均时间约为
12.324 s。
这表明 MPI 版本在本输入规模上获得了更好的扩展性。原因可能包括:
- MPI 版本按进程划分局部 CSR 数据,每个进程处理的数据规模更小,缓存行为可能优于共享内存版本;
- 当前矩阵带宽很小,跨进程 halo 通信量有限,计算划分收益较大;
- Pthread 版本中线程同步、共享数据结构和内存带宽竞争更集中,而 MPI 进程拥有更独立的地址空间;
- 当跨节点运行时,总内存带宽和总 CPU 资源增加,能进一步降低计算阶段时间。
不过 MPI 并非无条件优于 Pthread。低进程数、多节点低 ppn 的配置明显较慢,说明 MPI 程序对进程布局和资源使用方式更敏感。
6.8 分析框架:总时间由哪些部分构成
为了更系统地理解实验结果,可以将 MPI 程序总时间粗略拆成以下几部分:
T_total(P) = T_init(P) + T_io(P) + T_cg(P) + T_gather(P)其中:
T_init(P)表示 PBS 调度、MPI 进程启动和运行环境初始化开销;T_io(P)表示多个进程读取matrix.txt和vector.txt的开销;T_cg(P)表示 CG 迭代主体时间;T_gather(P)表示最后收集解向量和输出校验信息的开销。
进一步看 CG 迭代主体,又可以分解为:
T_cg(P) = N_iter * (T_spmv(P) + T_vec(P) + T_halo(P) + T_allreduce(P))其中 T_spmv 和 T_vec 是可并行计算部分,理论上会随 P 增大而下降;T_halo 是相邻进程之间的边界交换;T_allreduce 是所有进程参与的全局规约。实际加速比不可能线性增长,主要是因为:
- 每个进程分到的数据减少后,单个进程的计算时间下降,但通信和同步次数没有减少;
MPI_Allreduce需要所有进程等待彼此,最慢进程会拖住整轮迭代;- 多进程同时读大文件时,文件系统压力可能上升;
- 节点内进程过多时,CPU 缓存、内存带宽和 NUMA 访问都会影响性能;
- 节点数增加后,跨节点网络延迟和作业调度不确定性也会增加。
因此,本实验的结果不能只用“进程越多越快”来解释,而要同时考虑三类因素:
- 计算划分收益:更多进程可以分摊
SpMV和向量更新; - 通信同步成本:halo 交换和
MPI_Allreduce会随着进程数增加而更明显; - 运行环境开销:文件读入、PBS 调度、跨节点启动和节点内资源竞争都会进入
real时间。
下面各小节按照这个框架分析实验现象。
6.9 单节点扩展性分析
单节点结果总体上说明 MPI 并行化是有效的:从 1 进程到 2 进程,平均时间由 104.209 s 降到 55.464 s;到 4 进程时进一步降到 30.938 s;到 16 进程时达到 18.162 s。这说明当前按行分块后,SpMV 和向量更新的主要工作量确实被多个进程分摊。
不过,单节点结果中也有一个突出现象:8 进程平均时间 31.659 s,略慢于 4 进程的 30.938 s。从表面看,这似乎违反了“进程数增加应该更快”的直觉,但在并行程序中这是常见现象。
首先,4 进程到 8 进程时,每个进程分到的矩阵行数减半,计算量确实下降。但是,CG 每轮迭代中的 MPI_Allreduce 次数并不会随进程数减少,反而参与规约的进程更多。若单进程计算量下降后,规约和同步在总时间中的占比提高,那么加速收益就会被抵消。
其次,单节点上 MPI 进程共享同一套内存子系统。稀疏矩阵向量乘的计算强度并不高,它需要频繁访问 values、col_idx、row_ptr 和向量 p,更偏向内存访问型负载。当进程数增加到一定程度后,内存带宽和缓存层级会成为瓶颈,继续增加进程不一定能等比例提升吞吐量。
第三,从标准差看,8 进程的标准差只有 0.158 s,说明该结果并不是某一次偶然慢造成的,而是这一配置下较稳定的性能表现。也就是说,8 进程的相对变慢更可能来自系统性开销,而不是随机噪声。
最后,16 进程平均时间又下降到 18.162 s,说明 8 进程不是算法层面的绝对瓶颈点,而更可能是节点内资源映射、缓存竞争或运行时调度造成的局部不优。若进一步严格实验,可以增加进程绑定参数,例如 --bind-to core 或平台支持的 NUMA 绑定方式,观察 8 进程是否仍然慢于 4 进程。
6.10 多节点配置分析:节点数与 ppn 要配合
多节点实验中,nodes=2:ppn=1 和 nodes=4:ppn=1 的表现很差,平均时间分别为 137.267 s 和 169.824 s,均慢于串行基线。这是本实验最值得强调的现象之一,因为它说明“使用更多节点”不等价于“获得更高性能”。
这一现象可以从三个方面解释。
第一,ppn=1 时每个节点只使用 1 个 MPI 进程,节点内部大量核心处于空闲状态。虽然总节点数增加了,但总进程数仍然很少,例如 nodes=4:ppn=1 只有 4 个进程。对于一个每轮迭代都要规约的程序来说,跨 4 个节点使用 4 个进程,往往不如在单节点内紧凑使用 4 个进程。
第二,跨节点运行引入了更高的通信路径。即使 halo 交换数据很少,MPI_Allreduce 仍然要跨节点完成。节点间通信延迟通常高于节点内通信,因此低 ppn 配置下计算量不足以摊薄跨节点通信和启动成本。
第三,当前程序每个进程都要扫描输入文件的一部分。多节点同时访问共享文件系统时,文件系统调度、缓存命中和网络文件访问都会影响读入阶段。虽然报告使用的是 time 的 real 时间,包含了读入和初始化,因此低 ppn 配置的慢并不只代表 CG 计算慢,也包含了整个作业生命周期的额外成本。
当 ppn 增加后,多节点性能明显改善。例如 2 节点从 ppn=1 的 137.267 s 降到 ppn=8 的 13.112 s,4 节点从 ppn=1 的 169.824 s 降到 ppn=8 的 12.544 s。由此可见,多节点程序的合理使用方式通常不是“每个节点只开一个进程”,而是在每个节点上使用足够多的进程,使节点内部 CPU 和内存带宽被充分利用,同时控制跨节点通信的比例。
6.11 相同总进程数下的节点布局比较
在总进程数相同的情况下,不同节点布局会带来不同结果。以 16 个总进程为例:
- 单节点 16 进程:
18.162 s; - 2 节点
ppn=8:13.112 s; - 4 节点
ppn=4:15.178 s。
这说明适度跨节点可以改善性能。与单节点 16 进程相比,2 节点 ppn=8 将进程分散到两个节点上,能够获得更多总内存带宽和缓存资源,同时跨节点通信规模仍较可控,所以性能最好。
但继续分散到 4 节点并不一定更快。4 节点 ppn=4 的总进程数仍为 16,但需要跨更多节点参与 MPI_Allreduce,节点间通信路径更复杂,作业调度的不确定性也更大。因此它虽然快于单节点 16 进程,但慢于 2 节点 ppn=8。
对于 32 个总进程,2 节点 ppn=16 和 4 节点 ppn=8 的平均时间分别为 12.324 s 与 12.544 s,差距很小。这表明在更高进程数下,两种布局都已经接近该实现的扩展平台期。继续增加进程时,单纯扩大并行度可能收益有限,更需要减少全局规约次数、改进 I/O 或优化进程绑定。
6.12 加速比与效率的口径说明
单节点实验中,以 1 进程 MPI 为基线时,16 进程加速比为 5.738,并行效率为 0.359。这个结果说明程序获得了明显加速,但离理想线性加速仍有很大距离。
并行效率下降并不意味着并行化失败。对于 CG 这类迭代算法,全局规约是算法结构的一部分,不能简单消除。随着进程数增加,每个进程的本地计算减少,通信和同步在总时间中的比例自然上升。因此效率下降是符合预期的。
多节点表中还出现了效率大于 1 的情况,例如 2 节点 ppn=2 的同组效率为 1.034。这不是超线性加速的严格证明,而是因为该表以同节点数下 ppn=1 作为基线,而 ppn=1 本身非常慢,包含较多启动、I/O 和跨节点低利用率开销。当 ppn 从 1 增加到 2 时,不仅计算并行度增加,还改善了节点资源利用率,所以相对基线出现了超过理想模型的数值。
因此,在正式解释时应区分两类基线:
- 若以串行程序为基线,可以观察 MPI 程序相对原始串行实现的真实收益;
- 若以同节点
ppn=1为基线,可以观察在固定节点数下增加每节点进程数的收益。
两种口径回答的问题不同,不能混为一谈。
6.13 主要瓶颈归纳
综合前面的现象,本实验当前主要瓶颈可以归纳为三类。
第一类是 I/O 开销。当前 sparse.cpp 为了减少内存占用,采用局部 CSR 读取方式。每个进程只保存本地行块,这是正确的分布式设计方向。但是从代码结构看,各进程会分别扫描 matrix.txt,以定位自己需要的 values、row_ptr 和 col_idx 区间。由于 matrix.txt 约 800 MB,多进程重复扫描会给文件系统带来明显压力。
这种设计有一个取舍:优点是每个进程内存占用随进程数下降,不需要保存完整矩阵;缺点是启动阶段 I/O 可能较慢,尤其在多节点同时访问共享文件系统时更明显。如果只关注 CG 迭代本身,可以在程序输出中单独统计 CG time,排除读入时间;但本报告使用 time 的 real 时间,更接近用户实际提交作业后的总等待时间。因此 I/O 开销被纳入统计是合理的,只是在分析时要说明它不完全等价于计算核心性能。
第二类是全局通信开销。本实验矩阵为带状稀疏矩阵,因此每个进程只需要相邻进程的少量边界 p 值。当前程序设置 halo_width=16,对于带宽为 3 的矩阵是足够的。它让边界通信量近似为常数,不随矩阵规模线性增长。因此本实验中 halo 交换不是主要瓶颈。真正更难扩展的是 MPI_Allreduce,因为它需要所有进程参与,并且每轮 CG 至少需要两次全局规约。
第三类是节点内资源竞争。稀疏矩阵向量乘需要频繁访问 values、col_idx、row_ptr 和向量数据,计算强度不高,因此在单节点高进程数下容易受到内存带宽和缓存竞争影响。这也是单节点 8 进程表现不稳定、并行效率随进程数下降的重要原因之一。
针对这些瓶颈,后续优化可以考虑以下方案:
- 由
rank=0读取完整文件后,通过MPI_Scatterv分发局部块,减少共享文件系统并发读取; - 将输入文件改为二进制格式,减少文本解析成本;
- 预先生成按 rank 分块的数据文件,避免运行时扫描无关数据;
- 使用 MPI-IO,让各进程按偏移读取自己的数据块;
- 合并全局点积规约,或使用非阻塞规约与局部计算重叠;
- 使用进程绑定和 NUMA 亲和性设置,降低节点内资源竞争。
七、个人总结
这次实验的代码实现明显比上一次难很多,哪怕整体工程量还不算特别复杂,调试过程也很费劲。很多问题单看代码不一定看得出来,尤其是涉及 MPI 通信和多进程协作的时候,定位起来会比单机程序麻烦得多。通过这次实验,我也更直观地体会到 MPI 代码的调试难度确实很大。
另外这次第一次做了多节点测试,跑出来不少超出我原来认知的结果,也让我对并行计算有了比课堂内容更深入的理解。以前会觉得“进程越多应该越快”,但实际数据告诉我还要看通信、I/O、同步和节点配置,很多时候不是线性关系。
在写实验报告的过程中,我也顺便试用了 OpenAI 新出的 Image2 图形工具,整体效果挺不错的,对图表整理和展示帮助很大。总体来说,这次实验不只是把程序跑通了,更重要的是让我真正感受到并行程序从实现到调试、再到性能分析,完整走一遍有多不容易,也很有收获。