1. 摘要
Transformer 已经是 NLP(自然语言处理)领域的"标配"(如 BERT, GPT 系列), 但在 CV 中长期以"局部改造"的方式出现: 要么与 CNN 组合, 要么在 CNN 中以注意力替换部分卷积, 整体框架仍以卷积为主。ViT 证明: 对卷积的依赖并非必需。只要把图像切成若干 patch 并喂给一个纯 Transformer Encoder, 图像分类同样可以取得很强的表现.
2. 导言
在 NLP 中, 随着数据和模型规模增大, Transformer 的性能往往"稳步上行、未见饱和"。把它直接搬到视觉, 首先会遇到一个核心难点: 如何把 2D 图像转换为 1D 序列?
- 直觉做法是把每个像素当作序列元素, 直接展平整张图再送入 Transformer。但复杂度会爆炸: 分类常用输入 展平后序列长达 , 约为 BERT 的 100 倍; 检测/分割常用的更大分辨率(如 )会更夸张.
- 因此在 ViT 之前, 视觉主流仍是 AlexNet, ResNet 等 CNN; 注意力相关的工作要么与 CNN 混用, 要么尝试"全注意力"的替换(如 Stand-Alone Attention, Axial Attention), 但整体仍未"完全 Transformer 化".
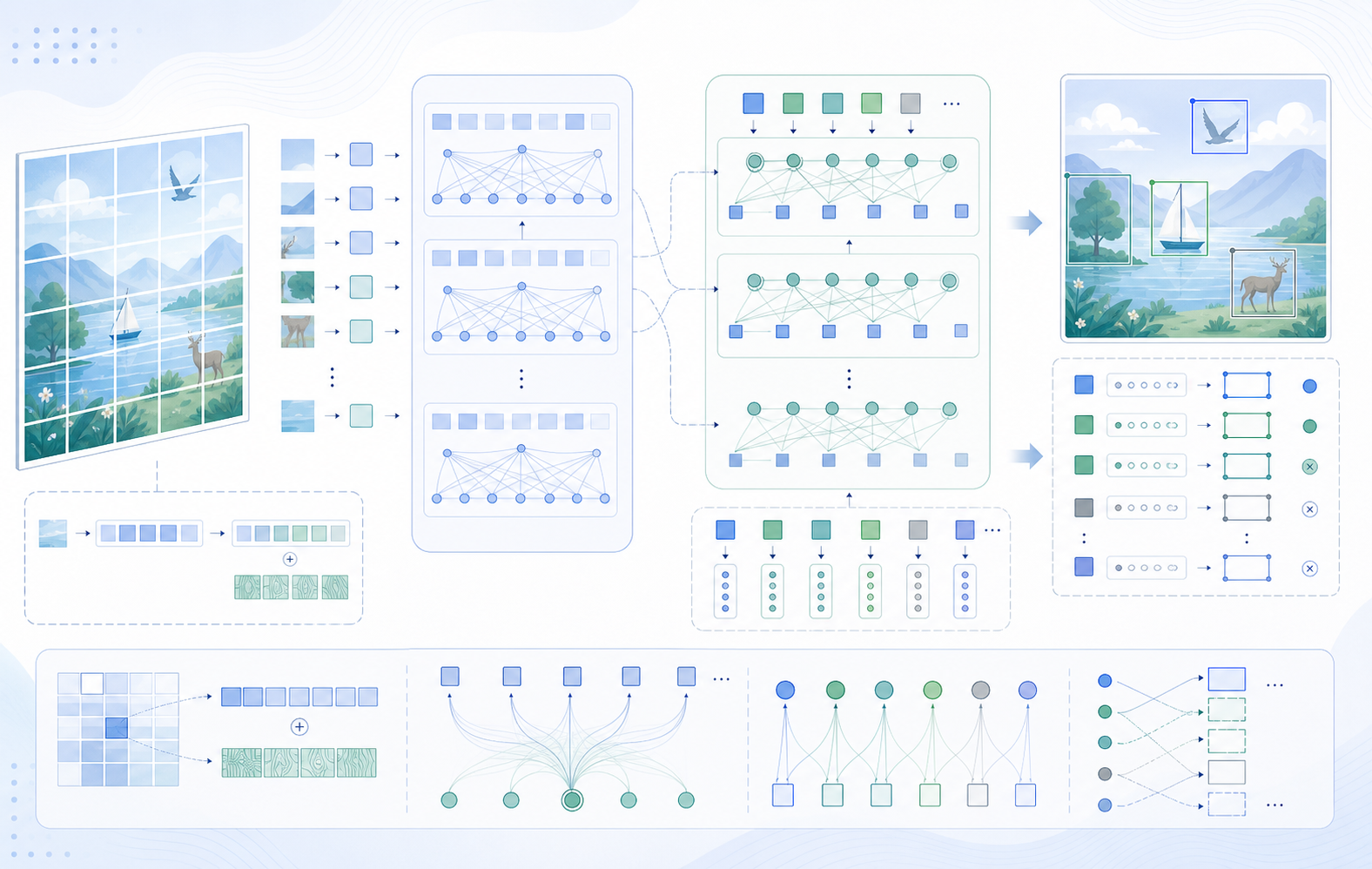
ViT 的关键点是: 把图像切分为固定大小的 patch, 把每个 patch 线性映射为一个 token, 组成可被标准 Transformer 处理的序列。以 输入, patch 大小 为例, 网格为 , 序列长度 , 对常规模型是完全可控的.
我们把每个 patch 视为一个"单词", 通过一个全连接层(FC layer)得到线性嵌入(patch embedding), 作为 Transformer 的输入。训练是有监督的分类训练.
在中等规模数据集(如 ImageNet)上, 如果不采用较强的数据增强/正则, ViT 往往比同规模 ResNet 略弱。这并不意外: 相对 CNN, Transformer 缺少若干"图像归纳偏置".
所谓归纳偏置(inductive bias), 可以理解为我们对数据结构的先验假设。以 CNN 为例:
- 局部性(locality): 以滑窗卷积处理, 相邻区域特征相关;
- 平移等变性(translation equivariance): 可近似理解为 , 先平移再卷积与先卷积再平移的效果接近.
正因 CNN 携带这些先验, 它在数据有限时更稳。而 ViT 只要有足够数据进行预训练, 再在下游迁移微调, 就能取得非常好的泛化与可扩展性。某种意义上, 它把 NLP 与 CV 的"范式"连通了: 使用几乎"原味"的 NLP Transformer 架构, 只在 patch 抽取与位置编码处保留少量图像特有的设定, 就能在大规模预训练的加持下, 在多项图像分类基准上达到或超过以往方法.
3. ViT 模型

在模型设计上, 尽量沿用"原始的 Transformer Encoder 堆叠".
好处: 可以直接复用 NLP 领域已被充分验证的模块与训练技巧, 工程与实验成本更低.
3.1 Patch 切分与线性嵌入
给定一张输入图, 将其切分为若干 的 patch; 把这些 patch 依序展平成 token, 并通过线性投射层得到 patch embedding。由于自注意力天然是"全互联", 并不自带顺序信息, 因此需要为每个 token 额外加入位置编码(position embedding), 让序列既包含局部图像信息, 也编码其在整幅图中的相对位置.
为实现分类, ViT 在序列最前加入一个可学习的分类标记 CLS。它与其他 token 一同参与多头自注意力交互; 直觉上, [CLS] 会从所有 patch token 聚合全局语义。最终使用 [CLS] 对应的向量, 接一个 MLP head(分类头)进行预测, 训练时采用交叉熵损失.
提示: 实践中, patch embedding 既可用"线性层 + 展平"实现, 也可等价地用 Conv2d(kernel=stride=patch_size)实现, 后者在工程上更高效.
3.2 序列构建与位置/分类标记
把上一步得到的 patch embedding 按顺序排成长度为 的序列(典型 ), 在首位拼接 1 个 [CLS], 再与位置编码逐元素相加:
- Token 组成: .
- 位置编码: 采用可学习的绝对位置编码(learned absolute PE), 即 , 与 token 向量逐元素相加得到 。当分辨率变化时, 常通过双线性插值对 进行适配.
- 分类标记: [CLS] 自身有其可学习的向量表示, 其位置索引固定在序列首位, 对应的可学习位置编码也会随训练一并更新。
说明(直观类比): 可以把 [CLS] 想象成“先上车、再打工、最后当代表”:它先被加入序列(上车),在 Transformer Encoder 的每一层与所有 patch token 进行自注意力交互(在车上打工,持续收集信息),但直到 Encoder 的最终输出出来后,[CLS] 对应的向量才携带足够的全局语义用于最终的分类决策(代表发言)。换言之,[CLS] 在整个编码过程中不断聚合信息,但只有经过多层注意力汇聚后的向量才真正承载可用的类别信息。
实践小贴士: 在微调或迁移学习时,可以对分类 head(接在 [CLS] 上的 MLP/线性层)做单独学习率或先冻结底层再微调的策略;如果更倾向稳健聚合,也可以考虑用 GAP(global average pooling) 作为替代或与 [CLS] 联合使用。
补充: 也有工作采用相对位置编码或二维位置编码(将 2D 网格映射为 1D 序列后仍保留二维位置信息), 迁移到不同分辨率时往往更平滑.
3.3 Transformer Encoder 与分类头
设输入图像 , 以 切分得到 个 patch。展平后每个 patch 的维度为 ; 令线性投射矩阵 (典型 ), 则拼接后的矩阵 经投射后为 。再拼接 1 个 [CLS] 并与位置编码相加, 得到形状 的序列(典型为 ).
每个 Transformer 编码块通常采用 Pre-LN: 先做 LayerNorm, 再进行多头自注意力(MHA), 接残差; 随后再一次 LayerNorm + MLP(前馈网络) + 残差。MHA 中, 会从输入构造 , 分成 个头后, 每个头的维度为 。例如 , 则 ; 各头输出拼接回 维.
MLP 通常采用"扩展再压回"的两层结构, 扩展比约为 , 即 ; 常结合 GELU, Dropout/DropPath 等正则化。堆叠 个这样的编码块即构成 ViT 主体.
分类时, 读取最终层 [CLS] 对应的向量, 接 MLP head 得到类别分布。需要时, 也可用 GAP(global average pooling)对所有 token 汇聚替代 [CLS] 方案.
4. 训练与数据规模
在中型/中等规模的数据集(比如 ImageNet)上, 如果不加比较强的数据增强/正则化, ViT 往往比同等大小的残差网络弱一些。这并不意外: Transformer 相比 CNN 缺少某些"内置"的图像归纳偏置(如局部性/平移等变), 需要更多数据与正则来支撑。一旦引入大规模的预训练, 再在下游任务上做迁移微调, 常能取得非常好的效果.
5. 与 CNN 的归纳偏置
归纳偏置可以理解为一种先验或假设。对 CNN 来说, 两个典型的 inductive bias 是:
- 局部性(locality): CNN 以滑动窗口在图片上卷积, 相邻区域特征相关;
- 平移等变性(translation equivariance): 可近似理解为 , 先平移还是先卷积, 最终效果接近.
正因为 CNN 拥有这些归纳偏置, 它相当于自带"先验", 在数据量不那么大时更稳。而 ViT 在足够数据的预训练 + 迁移设置下, 能展现出与 NLP 中 Transformer 类似的可扩展性趋势.
6. 实践小抄
- 常用输入/patch: 224×224 输入, patch size=16 → 序列长度 196; 也可用 32 得到更短序列(更快, 但细节损失更多).
- 位置编码: 可学习 1D 编码(来自 2D 网格展平); 分辨率变化时需对位置编码做插值以适配.
- 分类标记: 默认使用 [CLS] 读取全局语义, 其向量接 MLP head/线性分类器; 也有人使用 GAP 替代.
- 训练建议: 强数据增强/正则(如 RandAugment, Mixup/CutMix, Label Smoothing, Stochastic Depth), 优化器优先 AdamW + warmup + cosine lr; 尽量采用"大数据预训练 + 迁移".
- 关键超参: 层数(L), 隐藏维度(D), 头数(H), 每头维度 , MLP 扩展比(常用 4×).
7. 参考文献
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929. arXiv