用 Pthread 计算 sin(x):四种同步策略的并行性能对比
这次并行计算实验,我选的题目是“多线程计算正弦值”。题目本身不复杂:用正弦函数的泰勒展开式近似计算 sin(x),然后用 Pthread 把计算并行化,再比较不同线程同步策略带来的性能差异。
真正有意思的地方不在“能不能并行”,而在“怎么并行更合适”。同样是多线程,有的实现把时间花在计算上,有的实现把时间花在锁竞争和缓存一致性上。这个实验的价值,也正在于把这些差异跑成可观察的数据。
1. 问题是什么
实验输入包含三个参数:
- 弧度值
x - 展开上界
N - 线程数
T
计算目标是:
从源码实现看,程序实际按照 i = 0 到 i <= N 累加,因此当 N = 100000 时,实际计算的是 100001 项。
每一项都可以独立计算,所以这个问题天然适合做数据并行。不过,项与项之间的计算开销并不一致。第 i 项要做 2i+1 次乘法,越往后单项越重。如果简单按连续区间切分,很容易导致后面的线程更忙、前面的线程更早结束。
2. 我为什么选“循环划分”
这次实验里,我采用的是循环划分,也就是把级数项按线程编号轮转分配:
- 线程 0 负责
0, T, 2T, ... - 线程 1 负责
1, T+1, 2T+1, ... - 线程 2 负责
2, T+2, 2T+2, ...
这样做的好处很直接:大项和小项会被交错分配给不同线程,负载更均衡。
流程图如下:
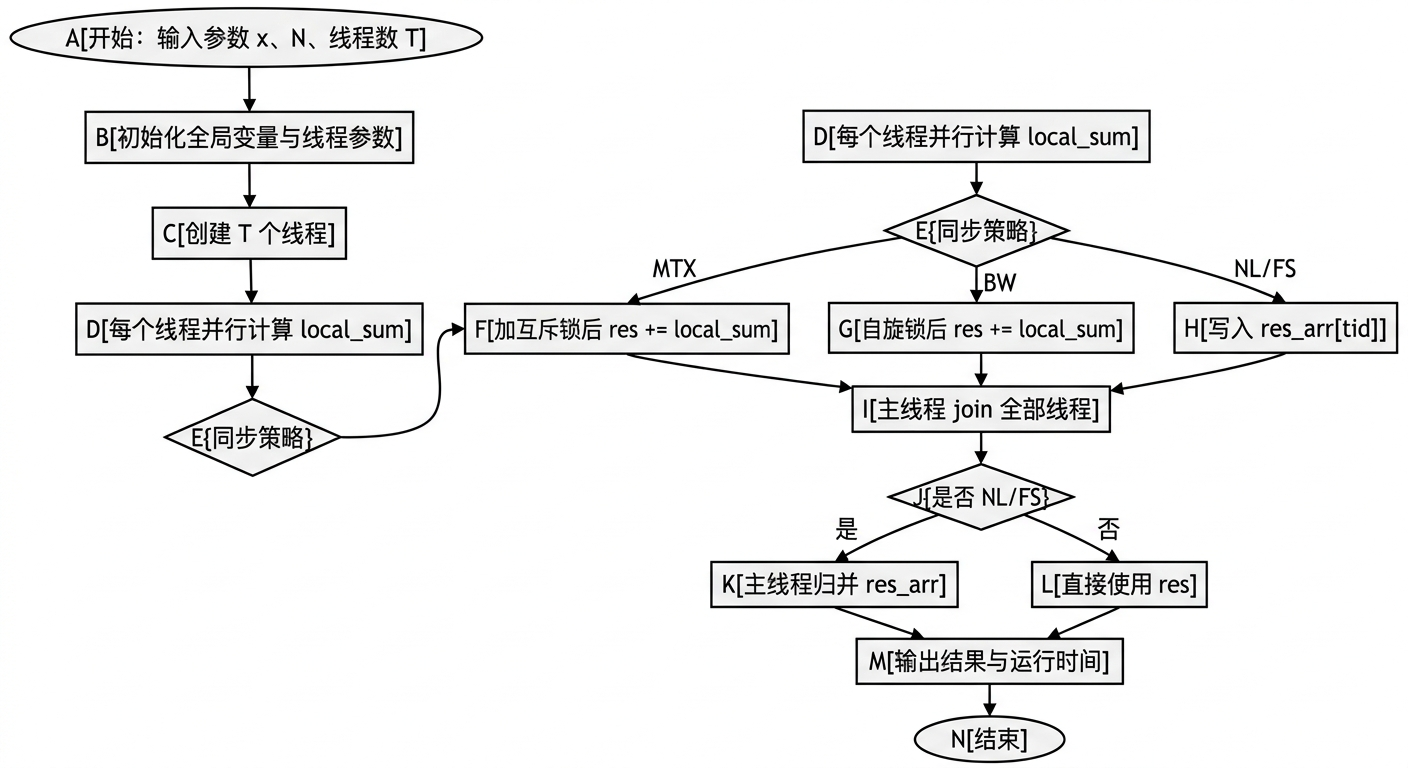
核心循环可以概括成下面这样:
for (i = arg->begin; i <= arg->max_n; i += arg->step) {
tmp = 1.0;
for (j = 1; j <= 2 * i + 1; j++) {
tmp *= arg->radian / j;
}
if (i % 2 > 0) {
local_sum -= tmp;
} else {
local_sum += tmp;
}
}这段逻辑决定了实验的基本性能特征:计算量足够大,并且线程内部主要是算术运算,因此很适合观察同步机制对总耗时的影响。
3. 四种实现策略
这次实验一共做了四个版本,重点不是比“谁能跑出来”,而是比“谁的同步代价更低”。
在进入不同同步策略之前,先看一下几个版本共享的主线程框架。四个程序的主体结构基本一致,都是:
- 读取命令行参数
- 初始化线程参数
- 创建
pthread - 等待所有线程结束
- 根据不同方案决定是否再做一次主线程归并
主线程核心代码大致如下:
typedef struct Args {
float radian;
long max_n;
long begin;
long step;
} Args;
int main(int argc, char *argv[]) {
long i;
double radian = atof(argv[1]);
long max_n = atol(argv[2]);
int threads = atoi(argv[3]);
Args *arg;
pthread_t *pid;
pid = (pthread_t *)malloc(threads * sizeof(pthread_t));
for (i = 0; i < threads; i++) {
arg = (Args *)malloc(sizeof(Args));
arg->radian = radian;
arg->max_n = max_n;
arg->begin = i;
arg->step = threads;
pthread_create(&pid[i], NULL, cal, (void *)arg);
}
for (i = 0; i < threads; i++) {
pthread_join(pid[i], NULL);
}
}这里最关键的是:
begin = i指定线程从第几个级数项开始step = threads保证线程按固定步长轮转取任务- 每个线程都只处理自己的项序列,不需要在计算阶段互相协调
3.1 nl:无锁归并
nl 的思路最直接。每个线程先把自己的结果算到局部变量 local_sum,最后只写一次 res_arr[tid],主线程在 join 之后统一归并。
local_sum = 0.0;
for (i = arg->begin; i <= arg->max_n; i += arg->step) {
...
}
res_arr[arg->begin] = local_sum;这个版本几乎没有线程间同步,理论上应该是很标准的共享内存归约写法。
把它展开一点,实际工作线程长这样:
void *cal(void *_arg) {
long i, j;
double tmp, local_sum;
Args *arg = (Args *)_arg;
local_sum = 0.0;
for (i = arg->begin; i <= arg->max_n; i += arg->step) {
tmp = 1.0;
for (j = 1; j <= 2 * i + 1; j++) {
tmp *= arg->radian / j;
}
if (i % 2 > 0) {
local_sum -= tmp;
} else {
local_sum += tmp;
}
}
res_arr[arg->begin] = local_sum;
free(arg);
return NULL;
}主线程最后再统一求和:
for (i = 0; i < threads; i++) {
res += res_arr[i];
}
printf("%lf\n", res);这也是为什么 nl 从结构上看最“干净”。
3.2 mtx:互斥锁归并
mtx 的做法是每个线程先完成局部求和,最后只在归并阶段进入一次临界区:
pthread_mutex_lock(&lock);
res += val;
pthread_mutex_unlock(&lock);它虽然用了锁,但锁的进入次数非常少,临界区也非常短,所以未必会很慢。
对应的线程函数片段如下:
void *cal(void *_arg) {
long i, j;
double val, tmp;
Args *arg = (Args *)_arg;
val = 0.0;
for (i = arg->begin; i <= arg->max_n; i += arg->step) {
tmp = 1.0;
for (j = 1; j <= 2 * i + 1; j++) {
tmp *= arg->radian / j;
}
if (i % 2 > 0) {
val -= tmp;
} else {
val += tmp;
}
}
pthread_mutex_lock(&lock);
res += val;
pthread_mutex_unlock(&lock);
free(arg);
return NULL;
}注意这里的关键点不是“用了锁”,而是“只在最后用一次锁”。如果把锁放到内层循环里,每算一项就加锁,这个版本的结果会差很多。
3.3 bw:忙等待自旋锁归并
bw 和 mtx 的结构基本一致,只是把互斥锁换成了自旋锁:
while (__sync_lock_test_and_set(&spin_lock, 1)) {
}
res += val;
__sync_lock_release(&spin_lock);如果临界区很短,自旋锁理论上可能避免线程睡眠和唤醒的代价;但如果竞争明显,它也会额外消耗 CPU。
它在源码里是这样定义的:
double res;
volatile int spin_lock = 0;然后在线程结束时手动做加锁和释放:
while (__sync_lock_test_and_set(&spin_lock, 1)) {
}
res += val;
__sync_lock_release(&spin_lock);这个版本很适合和 mtx 对照看,因为两者除了锁实现之外,几乎没有别的结构差异。
3.4 fs:伪共享实验版本
fs 版本不做局部归约,而是在循环内部直接更新 res_arr[tid]:
if (i % 2 > 0) {
res_arr[arg->begin] -= tmp;
} else {
res_arr[arg->begin] += tmp;
}虽然不同线程写的是不同数组元素,但这些元素可能落在同一条 cache line 上,于是会引入典型的伪共享问题。这个版本的目的,就是故意把这种缓存一致性开销放大出来。
这一版完整一点的核心代码如下:
void *cal(void *_arg) {
long i, j;
double tmp;
Args *arg = (Args *)_arg;
for (i = arg->begin; i <= arg->max_n; i += arg->step) {
tmp = 1.0;
for (j = 1; j <= 2 * i + 1; j++) {
tmp *= arg->radian / j;
}
if (i % 2 > 0) {
res_arr[arg->begin] -= tmp;
} else {
res_arr[arg->begin] += tmp;
}
}
free(arg);
return NULL;
}和 nl 相比,最大的区别就是 fs 没有先放到线程私有变量里累计,而是每轮循环都直接写共享数组。这正是它容易出现伪共享的原因。
4. 实验环境与测试方法
实验运行在学院平台管理中心提供的高性能计算集群上,报告中给出的环境如下:
- 集群结构:1 个管理节点 + 7 个计算节点
- CPU:
2 × Intel(R) Xeon(R) Gold 5218 - 内存:
256 GB - 硬盘:
3 × 600 GB - 存储方式:RAID5,可用容量约
1.2 TB
程序使用 C++ + Pthread 实现,作业通过 PBS 提交。为了稳定收集数据,我还写了一个批量提交脚本 start.sh,用来重复提交同一个 PBS 文件并限制最大并发作业数。
批量提交脚本的核心逻辑如下:
while true; do
running=0
for id in "${jobids[@]:-}"; do
status="$(qstat "$id" 2>/dev/null | awk 'NR==3 {print $5}' || echo "X")"
if [[ "$status" == "R" || "$status" == "Q" ]]; then
running=$((running + 1))
fi
done
if [[ $submitted -lt $REPEAT_TIMES ]] && [[ $running -lt $MAX_JOBS ]]; then
submit_out="$(qsub "$PBS_FILE" 2>&1)"
job_id="$(echo "$submit_out" | awk '{print $1}')"
jobids+=("$job_id")
submitted=$((submitted + 1))
continue
fi
if [[ $submitted -eq $REPEAT_TIMES ]] && [[ $running -eq 0 ]]; then
break
fi
sleep 2
done这个脚本的作用不在算法本身,而在于把实验过程自动化。对这种需要重复运行 10 次以上的性能测试来说,自动提交和控制并发能省很多时间。
本次统计口径如下:
- 固定输入:
x = 3.14 - 展开规模:
N = 100000 - 线程数:
1 / 2 / 4 / 8 / 16 - 对比版本:
fs / mtx / nl / bw - 每组配置重复运行
10次,结果取平均
加速比和并行效率按下面的公式计算:
5. 实验结果
5.1 平均运行时间
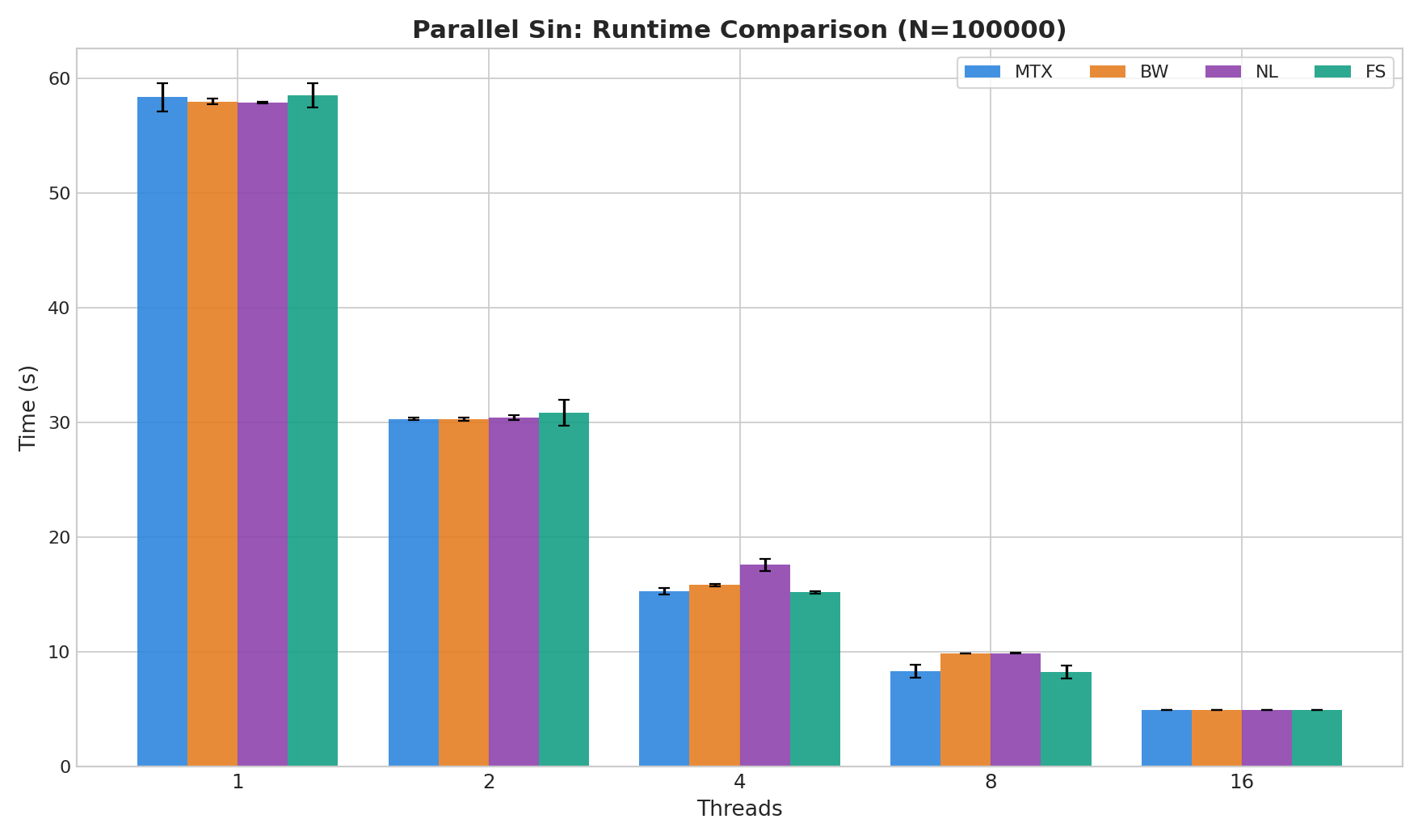
下面这张表汇总了四种方案在不同线程数下的平均耗时:
| 方案 | 1 线程 | 2 线程 | 4 线程 | 8 线程 | 16 线程 |
|---|---|---|---|---|---|
fs | 58.5212s | 30.8419s | 15.2019s | 8.2659s | 4.9735s |
mtx | 58.3452s | 30.3030s | 15.2908s | 8.3484s | 4.9665s |
nl | 57.8847s | 30.4238s | 17.5954s | 9.8970s | 4.9783s |
bw | 57.9764s | 30.2796s | 15.8410s | 9.8828s | 4.9750s |
整体趋势很清楚:
- 线程数增加后,四个版本都获得了明显加速
4到8线程阶段,各方案差异开始拉开- 到
16线程时,四组结果又重新收敛到约4.97s
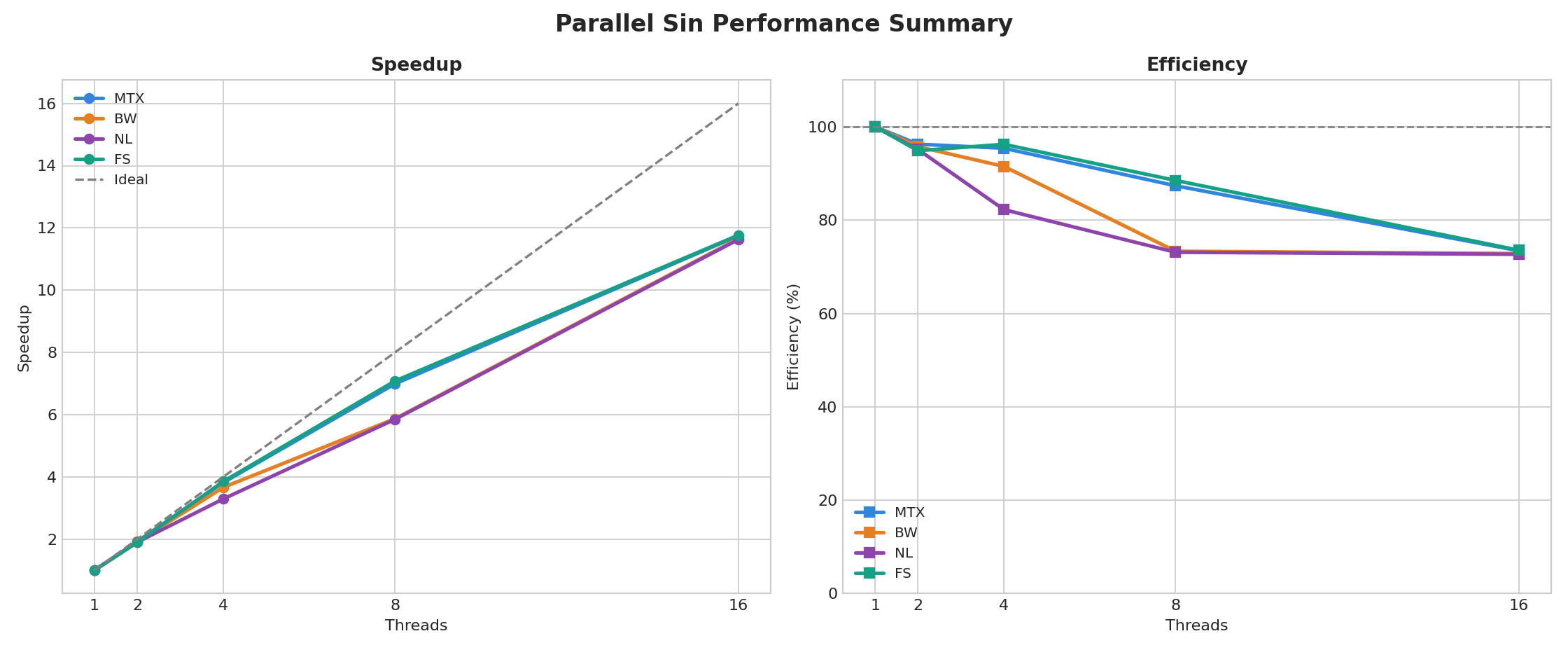
总览图如下:
5.2 以 mtx 为例看加速比和效率
mtx 组是这次实验里表现比较稳定的一组,它的关键结果如下:
| 线程数 | 平均时间 | 加速比 | 并行效率 |
|---|---|---|---|
| 1 | 58.3452s | 1.0000 | 1.0000 |
| 2 | 30.3030s | 1.9254 | 0.9627 |
| 4 | 15.2908s | 3.8157 | 0.9539 |
| 8 | 8.3484s | 6.9888 | 0.8736 |
| 16 | 4.9665s | 11.7477 | 0.7342 |
对应图表如下:
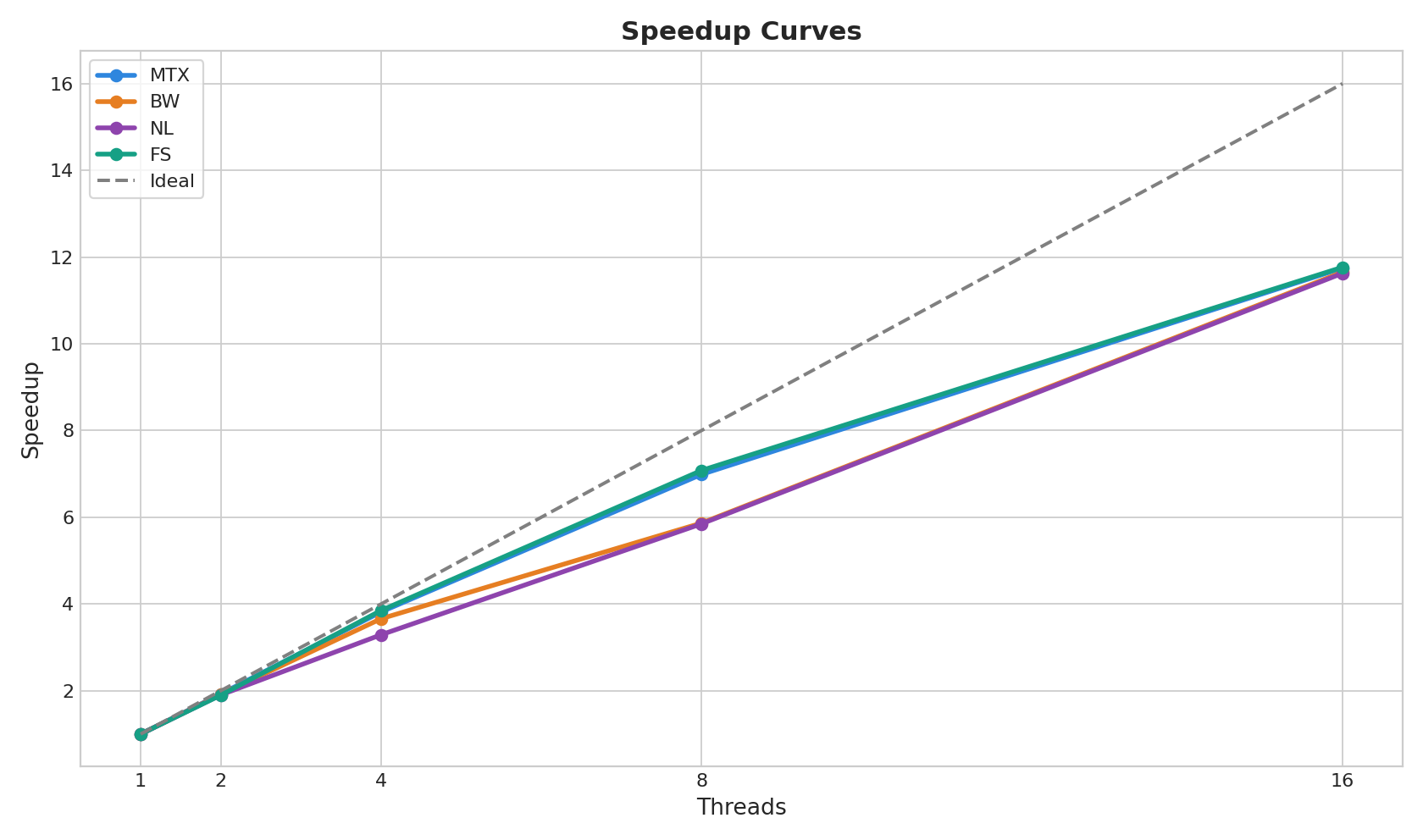
可以看到几个关键点:
- 从
1线程到16线程,运行时间从58.3452s降到4.9665s - 加速比最高达到
11.7477 - 并行效率则从接近
1逐步下降到0.7342
这说明并行化确实有效,但线程数变多以后,调度、同步和串行部分的影响也会越来越明显。
5.3 四种策略放在一起看
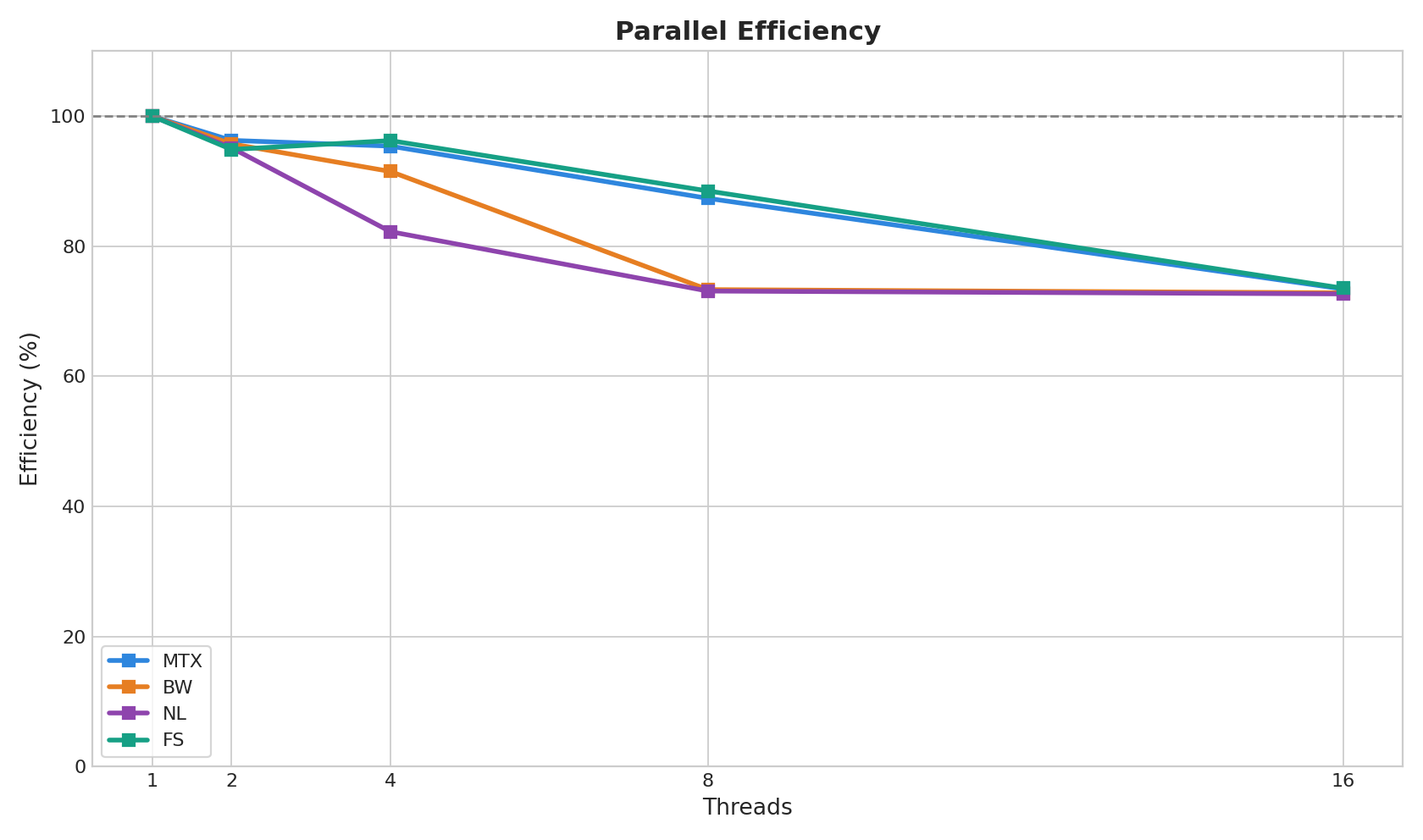
如果把四组数据放在一起观察,我觉得最值得记录的是下面几个现象。
第一,四个版本都拿到了不错的并行加速。到了 16 线程时,加速比基本都在 11.6 到 11.8 之间,说明这个问题本身具有很好的可并行性。
第二,mtx 并没有表现出直觉上的“锁一定更慢”。原因也很简单:它不是每算一项就加锁,而是每个线程先局部求和,最后只在结束时进入一次临界区。锁进入次数少,临界区短,互斥锁开销被大量计算掩盖了。
第三,bw 和 mtx 的差距并不大,甚至 mtx 略优。这说明在这个实验里,锁类型不是决定性因素,真正关键的是锁进入频率和临界区长度。
第四,fs 没有表现出预想中的明显最差。理论上它更容易触发伪共享,但从当前数据看,它在 4 线程和 8 线程阶段反而比较靠前。这说明伪共享虽然是一个真实风险,但它是否会成为主导瓶颈,仍然取决于具体平台、样本波动和整体计算占比,不能只凭经验判断。
第五,nl 在 4 线程和 8 线程时反而弱于 mtx 和 fs。这也提醒我,理论上“无锁更好”并不一定会直接体现在最终结果里,实际性能仍要以实验数据为准。
6. 这次实验真正说明了什么
如果只看最终结论,我认为这次实验至少说明了三件事。
6.1 计算密集型任务非常适合并行化
这个问题的主开销来自每一项中的大量乘法运算。只要任务划分合理,多线程确实可以明显缩短总时间。
6.2 同步机制的设计比“有没有锁”更重要
这次实验里,性能最好的并不是“完全无锁”的绝对理想模型,而是“局部计算 + 最后一次归并”的实现思路。换句话说,降低同步频率往往比单纯更换锁类型更有效。
6.3 伪共享和缓存问题必须靠实验验证
从理论上看,fs 的写法明显更危险;但从实际结果看,它并没有稳定地成为最差方案。这说明共享内存程序里的性能问题并不总能靠直觉判断,最终还是要回到真实平台上的测试数据。
7. 还能怎么继续优化
这份实验已经验证了并行化有效,但代码本身还有不少优化空间。
- 目前每一项都从头计算
x^(2i+1)/(2i+1)!,重复工作很多,可以考虑用递推关系减少乘法次数 - 可以针对
fs版本显式做 cache line padding,再重新测试伪共享是否被削弱 - 可以把线程创建成本和计算成本进一步拆开,分析不同线程数下的时间占比
- 如果继续扩展实验,也可以加入 OpenMP 或 SIMD 版本做更横向的比较
8. 总结
这次实验让我对并行程序的理解更具体了一些。以前我更容易把“开多线程”理解成一个简单的加速开关,但实际做完以后会发现,真正拉开差距的是任务划分、归并方式、锁进入频率,以及缓存层面的细节。
同一个 sin(x) 计算题,换一种同步策略,性能表现就会明显不同。也正因为这样,并行计算的重点从来不只是“能跑”,而是“为什么这样写”“瓶颈到底在哪里”“数据为什么会长成这样”。

